Basic Mapping Skills with Python#
Maps#
Maps are visual representations of geographic or spatial information. They are used to display the physical features of an area, such as terrain, bodies of water, and landmarks, as well as human-made features like roads, buildings, and cities. Maps can be created at a range of scales, from small-scale world maps that show the entire planet, to large-scale maps that show detailed information about a single city block.
In addition to traditional maps that display physical features, there are also thematic maps that display specific types of data, such as population density, climate, or political boundaries. These maps use different colors, symbols, and shading to display the data, and are useful for understanding patterns and trends in the data.
Map data, also known as spatial data, is typically stored in a geographic information system (GIS) or a database with spatial capabilities. This allows the data to be analyzed and visualized in a spatial context, which can provide insights and information that might not be apparent in a non-spatial format. There are a number of types of files in which spatial data can be stored such as geojson, shape, and kml. Spatial data can also simply be stored in CSV files but will lack much of the functionality of other file formats.
This guide will go over how to make maps with Python using different file types. We will focus on two of the more common types of maps, choropleth, and proportional dot maps.
Creating Maps from CSVs with Plotly#
For the first two maps, we will be using data from a csv cotaining data on Covid 19 deaths in the United States. To get started, go ahead and import the modules below. As a disclaimer, this guide assumes you are using Anaconda. If you are not, you may need to install these modules with the ‘pip install’ command. If you need extra help with this step, consult Python’s guide on this topic.
%pip install plotly
%pip install nbformat
import pandas as pd
import plotly
import plotly.express as px
import plotly.io as pio
pio.renderers.default = 'notebook'
Start by reading the CSV into a variable using the pandas read_csv function. This will put everything into a dataframe object. The first row will be automatically read in as headers unless specified not to. Make sure to look through the data to get a feel for how everything is laid out and see columns that could be used to create a map.
data = pd.read_csv(r'../Data_Visualization/united_states_covid19_cases_deaths_and_testing_by_state.csv')
data.head()
| Code | State/Territory | Total Cases | New Cases in Past Week | Case Rate per 100000 | Total Deaths | New Deaths in Past Week | Death Rate per 100000 | Weekly Cases Rate per 100000 | Weekly Death Rate per 100000 | Total % Positive | % Positive Last 30 Days | % Positive Last 7 Days | # Tests per 100K | Total # Tests | # Tests per 100K Last 7 Days | Total # Tests Last 7 Days | # Tests per 100K Last 30 Days | Total # Tests Last 30 Days | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | AL | Alabama | 1627670 | 9820 | 33196 | 20892 | 10 | 426 | 200.3 | 0.2 | 10-14.9% | 10-14.9% | 10-14.9% | 182992.5722 | 9006038.0 | 798.19 | 39283.0 | 3324.41 | 163612.0 |
| 1 | AK | Alaska | 291752 | 692 | 39882 | 1436 | 0 | 196 | 94.6 | 0.0 | 8-9.9% | 15-19.9% | 15-19.9% | 648596.4730 | 4742265.0 | 686.86 | 5022.0 | 3147.47 | 23013.0 |
| 2 | AZ | Arizona | 2404386 | 3099 | 33033 | 32936 | 54 | 452 | 42.6 | 0.7 | 10-14.9% | 8-9.9% | 8-9.9% | 216526.7582 | 16069319.0 | 238.70 | 17715.0 | 1189.90 | 88307.0 |
| 3 | AR | Arkansas | 998837 | 1947 | 33098 | 12905 | 40 | 427 | 64.5 | 1.3 | 10-14.9% | 10-14.9% | 8-9.9% | 176011.8884 | 5334079.0 | 237.15 | 7187.0 | 1251.01 | 37912.0 |
| 4 | CA | California | 12023397 | 27118 | 30430 | 99695 | 294 | 252 | 68.6 | 0.7 | NaN | NaN | NaN | 430497.1708 | 169478462.0 | 981.87 | 386543.0 | 4650.75 | 1830909.0 |
The first map we will make is a choropleth map. A choropleth map is a type of thematic map that displays data using different shades or colors to represent values for different regions. These regions can be countries, states, counties, or any other type of geographic region. They are commonly used to display data such as population density, per-capita income, or voting patterns. The values for each region are typically represented by a color scale, with higher values shown in darker colors and lower values shown in lighter colors.
To make a choropleth you will need to use the choropleth() function in Plotly express. Set the locations parameter to the column with the region names or codes, and the color parameter to the column with the values you want to visualize. For this example, we will use “Code” for locations and “Total Deaths” for color. The parameter locationmode controls the set of locations used to match entries in locations to regions on the map. You can choose one of three options: ‘ISO-3’, ‘USA-states’, or ‘country names.’ For this example, we will use ‘USA-states.’ We will also need to set the scope to ‘usa’. See what happens when you delete either of these last two parameters from the code. For color_continuous_scale, we will use ‘viridis.’ However, use whatever color scale you like.
You also will want to update the margin with update_layout() and update the margin dictionary with values that will make the map easier to view. The keys in the dictionary are “r” for right, “l” for left, “t” for top, and “b” for bottom.
fig = px.choropleth(data, locations="Code",
color="Total Deaths",
hover_name="State/Territory",
color_continuous_scale='viridis',
locationmode= 'USA-states',
scope ='usa')
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()
The next map will be the proportional dot map. The proportional dot map is a type of thematic map that displays data using dots of varying sizes to represent values for different regions. Similar to a choropleth map, proportional dot maps can be used to display data such as population density, per-capita income, or voting patterns. However, instead of shading regions to represent values, proportional dot maps use individual dots to represent a set number of cases or occurrences for each region.
In a proportional dot map, each dot represents a fixed number of cases or occurrences, such as 10 or 100. The size of the dots is proportional to the total number of cases or occurrences for the region. For example, a region with 1,000 cases might be represented by 100 dots, while a region with 10,000 cases might be represented by 1,000 dots.
Proportional dot maps can be a useful tool for visualizing spatial patterns and trends, particularly when the data being displayed is highly clustered or concentrated in certain regions. They can also be used to display data for regions that are irregular in shape, such as cities or towns.
The proportional dot map can be made largely the same as the choropleth map. This time though, use the scatter_geo() function instead of choropleth(). The parameters are largely the same. However, scatter_geo color represents the dots on the map rather than the color of the region.
fig = px.scatter_geo(data, locations="Code",
color="Total Deaths",
hover_name="State/Territory",size="Total Deaths",
color_continuous_scale='viridis',
locationmode= 'USA-states',
scope ='usa')
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()
Why are CSV files not used as often for spatial data?#
CSV (Comma Separated Values) files are not as good for spatial data because they lack the additional information that is needed to accurately represent geographic features and their relationships to one another. CSV files are simply text files with rows and columns of data, and they do not have any built-in spatial reference information or the ability to store geometric data.
Spatial data, on the other hand, is complex and requires additional information to be properly represented. Spatial data often includes geographic coordinates (such as latitude and longitude) and topological relationships between geographic features (such as adjacency or containment). To store this information and accurately represent spatial data, specialized file formats are needed.
One common file format for spatial data is the shapefile format, which is commonly used in GIS (geographic information system) software. Shapefiles store not only the geographic coordinates of features, but also information about the shape, size, and attributes of those features. This makes them better suited for spatial analysis and visualization than CSV files.
In addition, there are other file formats designed specifically for spatial data, such as GeoJSON and KML, which also include spatial reference information and the ability to store geometric data. These file formats are more versatile and provide more functionality for spatial data analysis and visualization than CSV files.
Geopandas#
Geopandas is a Python library that provides tools for working with geospatial data in a tabular format. It is built on top of pandas and extends its functionality to include spatial data analysis. It provides a set of tools for working with vector data (e.g., points, lines, polygons) and includes functions for spatial operations such as spatial joins, buffering, and distance calculations. Geopandas uses the shapely library for handling geometric objects, and also includes support for reading and writing spatial data in various file formats. With geopandas, you can read, write, and manipulate vector data in a variety of formats, including shapefiles, GeoJSON, and others.
Geopandas provides a simple and efficient way to perform common spatial data operations, such as spatial joins, spatial buffering, and spatial overlays. It also supports advanced data analysis techniques, such as clustering and machine learning on spatial data.
Some of the key features of geopandas include:
- Reading and writing of spatial data formats
- Simple and efficient spatial data manipulation
- Support for a wide range of coordinate reference systems (CRS)
- Integration with popular data analysis libraries, such as numpy, scipy, and matplotlib
- Support for advanced spatial analysis techniques, such as kriging, clustering, and machine learning
As you go through this exercise, if you have experience with pandas, you will find geopandas and spatial files largely operate in the same way as pandas does with tabular data but with extra functionality.
If you do not have geopandas already installed you will need to install it. It does not automatically come built in with Anaconda. You will also need to install the descartes package to be able to plot polygons with geopandas. In the Anaconda command prompt, use the commented commands below to install the packages. If you are not using Anaconda, just use ‘pip install _______’ in your command prompt.
# conda install geopandas
# conda install -c conda-forge descartes
Once installed go ahead and import matplotlib.pyplot and geopandas.
%pip install geopandas
import matplotlib.pyplot as plt
import geopandas
Coordinate Reference Systems (CRS)#
A Coordinate Reference System (CRS) is a system that is used to define the positions of geographic features on the Earth’s surface. A CRS is based on a set of coordinates that specify a location in space, and a set of rules for interpreting those coordinates in terms of latitude, longitude, and elevation.
Many different CRSs are used in spatial data analysis and visualization, each with its own set of rules and conventions. The most commonly used CRSs are based on the WGS84 datum, which is a global standard for defining geographic coordinates.
The choice of CRS can have a significant impact on the accuracy and reliability of spatial data analysis and visualization. Different CRSs are used for different purposes, depending on factors such as the scale of the data, the geographic extent of the data, and the specific analysis or visualization task.
Some common types of CRSs include:
- Geographic CRSs: These are based on a spherical or ellipsoidal model of the Earth's surface, and are used to define positions on the Earth's surface in terms of latitude and longitude.
- Projected CRSs: These are based on a two-dimensional map projection of the Earth's surface, and are used to represent geographic features on a flat surface. Projected CRSs are commonly used for creating maps and visualizations.
- Local CRSs: These are used for defining positions relative to a specific location or area of interest, such as a building or a city block. Local CRSs are often used in urban planning and engineering applications.
Go ahead and create a variable equal to geopandas.readfile() equal to your file. Use the CRS function to learn more about our dataset. There is a lot of important information we can find on the CRS, axis, area of use, and datum. For this excercise, we will be using a simple shape file to explore the cartographic boundaries of the United States from the US Census Bureau.
states = geopandas.read_file(r'../Data_Visualization/cb_2018_us_state_500k.shp')
states.crs
Currently, the dataset is using the CRS EPSG:4269. For this exercise, we are going to change the CRS of this data to EPSG: 3395 using the to_crs() function. This will present our maps better on our screen. When we are creating our maps try switching back to EPSG: 4269 and see how it changes the view of the map. Use the crs function to see how the data has changed by changing the CRS.
# Assign WGS84 (most common for US Census shapefiles)
states.set_crs("EPSG:4326", inplace=True)
states = states.to_crs("EPSG:3395")
states.crs
<Projected CRS: EPSG:3395>
Name: WGS 84 / World Mercator
Axis Info [cartesian]:
- E[east]: Easting (metre)
- N[north]: Northing (metre)
Area of Use:
- name: World between 80°S and 84°N.
- bounds: (-180.0, -80.0, 180.0, 84.0)
Coordinate Operation:
- name: World Mercator
- method: Mercator (variant A)
Datum: World Geodetic System 1984 ensemble
- Ellipsoid: WGS 84
- Prime Meridian: Greenwich
Print out the head of the file and observe the data. Specifically, take a closer look at the geometry column. Notice how it does not just describe the location but also the shape. Spatial files such as shp and geojson have these specifications so when creating maps we will not only be able to plot the correct location but the correct shape as well. There are only three types of shapes geometry can fall under in spatial files: polygons, points, and multipolygons.
states.head()
| STATEFP | STATENS | AFFGEOID | GEOID | STUSPS | NAME | LSAD | ALAND | AWATER | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 28 | 01779790 | 0400000US28 | 28 | MS | Mississippi | 00 | 121533519481 | 3926919758 | MULTIPOLYGON (((-9852105.109 3509746.658, -985... |
| 1 | 37 | 01027616 | 0400000US37 | 37 | NC | North Carolina | 00 | 125923656064 | 13466071395 | MULTIPOLYGON (((-8429869.595 4266719.539, -842... |
| 2 | 40 | 01102857 | 0400000US40 | 40 | OK | Oklahoma | 00 | 177662925723 | 3374587997 | POLYGON ((-11466193.086 4347889.504, -11466151... |
| 3 | 51 | 01779803 | 0400000US51 | 51 | VA | Virginia | 00 | 102257717110 | 8528531774 | MULTIPOLYGON (((-8431606.067 4526190.756, -843... |
| 4 | 54 | 01779805 | 0400000US54 | 54 | WV | West Virginia | 00 | 62266474513 | 489028543 | POLYGON ((-9199798.73 4576931.13, -9199776.344... |
Now let’s go ahead and plot our map using the plot() function. Adjust the figure size to whatever you prefer. We will adjust the x and y limits by setting variables equal to the minimum and maximum bounds of the x and y axes of our data. You can then set new limits using set_xlim and set_ylim.
state_map = states.plot(figsize=(12, 12))
minx, miny, maxx, maxy = states.total_bounds
print(states.total_bounds)
state_map.set_xlim(minx, maxx)
state_map.set_ylim(miny, maxy)
[-19942765.32605051 -1626516.30297928 20012847.73599381
11487759.99204796]
(-1626516.3029792807, 11487759.992047962)
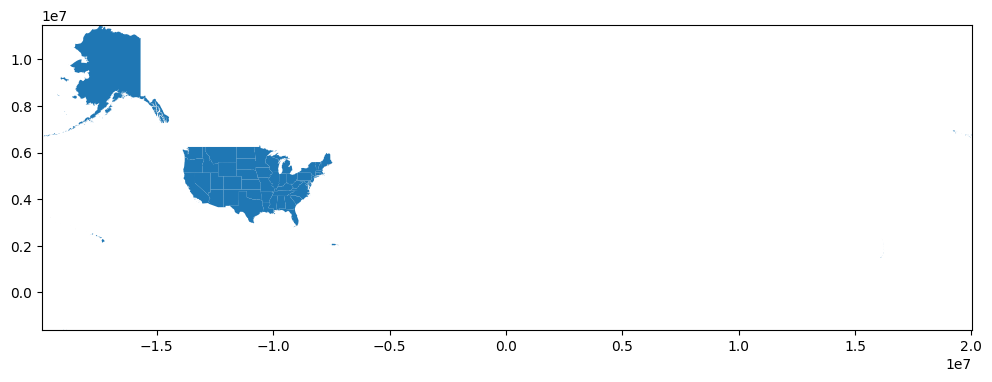
Notice how large are map above is? That’s because this dataset also includes US territories. Let’s focus our map on the 48 mainland states by dropping all non-mainland states and territories from the dataset. You can always print out the dataset to get through to make sure you got them all.
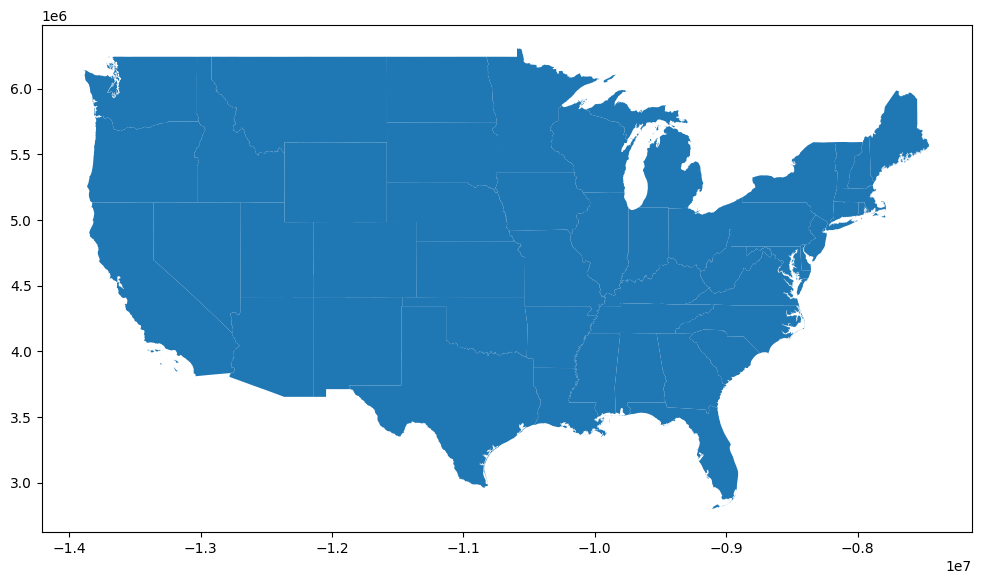
Now go ahead and replot the dataset and see how it changes.
dropped = states[(states["NAME"] == "Hawaii") | (states["NAME"] == "Alaska") | (states["NAME"] == "Guam") | (states["NAME"] == "Commonwealth of the Northern Mariana Islands")
| (states["NAME"] == "United States Virgin Islands") | (states["NAME"] == "Puerto Rico") | (states["NAME"] == "American Samoa")].index
states.drop(dropped, inplace=True)
state_map = states.plot(figsize=(12, 12))
If you just want to plot the boundary of your data, you can use ___.boundary.plot().
state_map = states.boundary.plot(figsize=(12, 12))
If you just want to plot just one state, you can use a conditional to just plot one state from your dataset.
states[states['NAME'] == 'South Carolina'].plot(figsize=(12, 12))
<Axes: >
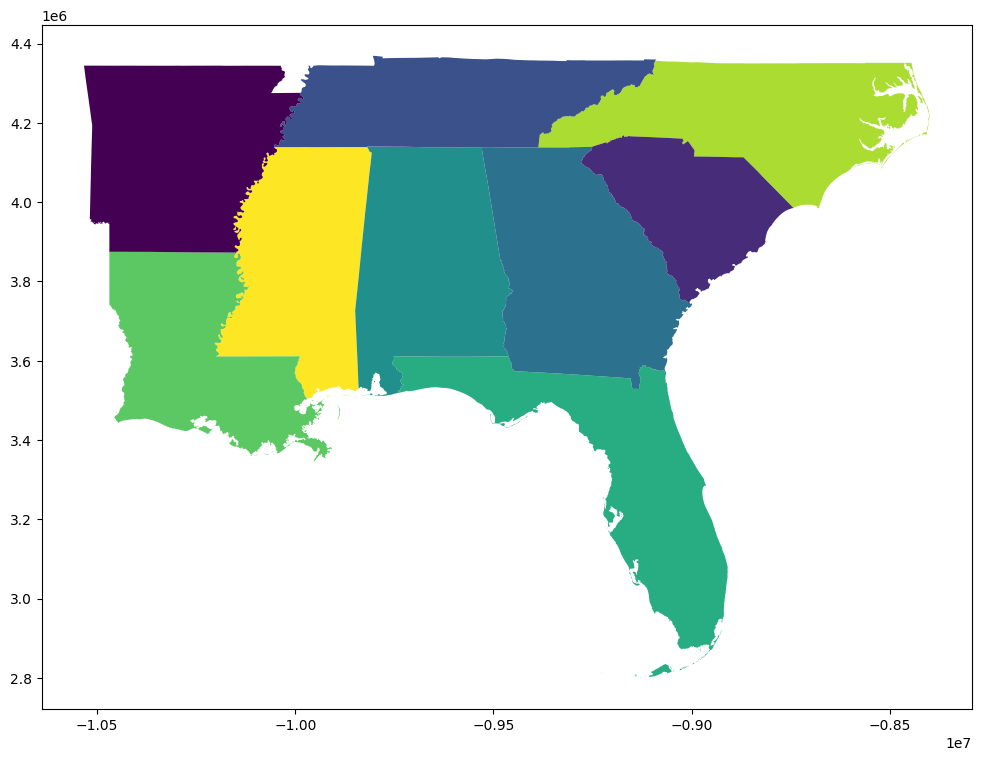
If you want to focus on a specific quadrant of the US, you can create a new dataset using the isin() function to select only states within a specific quadrant. After creating the new dataframe, use plot() to plot a new map of just the quadrant.
southeast = states[states['STUSPS'].isin(['FL','GA','AL','SC','NC', 'TN', 'AR', 'LA', 'MS'])]
southeast.plot(cmap = "viridis_r", figsize=(12,12))
<Axes: >
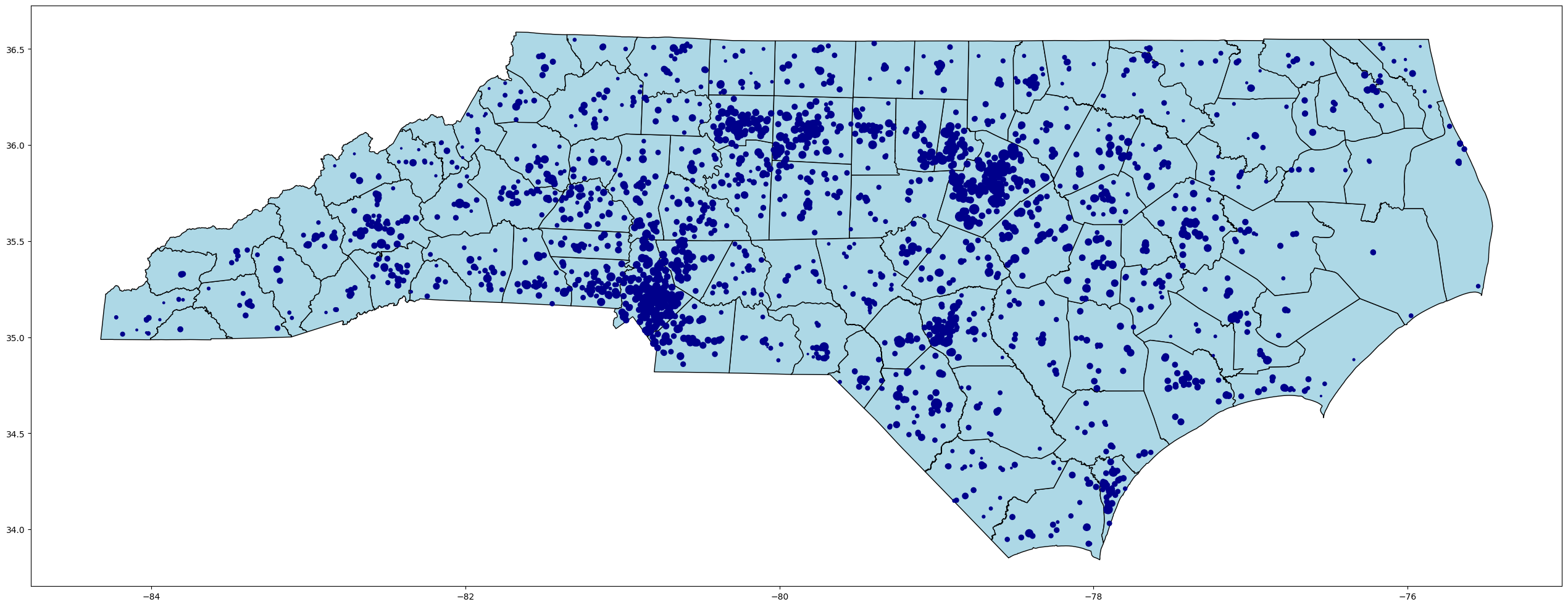
Plotting North Carolina Public Schools with Two GeoJson Files#
It is important to note that you can use multiple files to create a map. Let’s use a practical example to illustrate this. In this example, we will use two geojson files to make one map of North Carolina Public Schools found on NC OneMap.
Go ahead and read in the file “Public_Schools.geojson.” Go ahead and take a look at the data. Notice anything interesting about it?
nc_public_schools= geopandas.read_file(r'../Data_Visualization/Public_Schools.geojson')
nc_public_schools.head()
| objectid | lea_school | ptmoved | comments | reviewed | school_nam | principal | street_lon | phys_addr | phys_city | ... | ext_hours | num_teach | bgn_grade | end_grade | pre_k | elem | middle | high | early_coll | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 70310 | yes, 2012 | across town | 1 | B C Ed Tech Center | Willard Bryant | 820 North Bridge St | 820 North Bridge St | Washington | ... | - | 9 | 06 | 12 | yes | yes | POINT (-77.05613 35.55269) | |||
| 1 | 2 | 70340 | yes, 2012 | down the street | 1 | S W Snowden Elementary | Melissa Dana | 6921 NC 306 North | 693 North 7th Street | Aurora | ... | - | 15 | PK | 08 | yes | yes | yes | POINT (-76.79188 35.30652) | ||
| 2 | 3 | 70326 | Chocowinity Primary | Alicia Vosburgh | 606 Gray Road | 606 Gray Road | Chocowinity | ... | - | 33 | PK | 04 | yes | yes | POINT (-77.09387 35.49888) | ||||||
| 3 | 4 | 70308 | point verified | 1 | Bath Elementary | Pamela Hodges | 110 S King Street | 110 S King Street | Bath | ... | - | 39 | KG | 08 | yes | POINT (-76.81073 35.4758) | |||||
| 4 | 5 | 740309 | AydenGrifton High | Marty Baker | 7653 NC 11 South | 7653 NC 11 South | Ayden | ... | - | 48 | 09 | 12 | yes | POINT (-77.43122 35.43017) |
5 rows × 33 columns
Go ahead and plot the data. Notice how all the data is plotted as points? That is because all values in the geometry column are points, not polygons. You can vaguely tell it is NC but it is difficult to see where exactly the schools are located.
nc_public_schools.plot(figsize=(12,12))
<Axes: >
Now let’s read in “nc_boundaries.geojson” and look at the data. This time the data is all polygons. However, this dataset contains no information related to schools.
nc_counties = geopandas.read_file(r'../Data_Visualization/ncgs_state_county_boundary_-1613362181355057537.geojson')
nc_counties.head()
| OBJECTID | County | FIPS | Rec_Survey | NCGS_url | ck_date | geometry | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | Alamance | 001 | Recorded survey data is available. Visit North... | https://ncem-gis.maps.arcgis.com/apps/webappvi... | Mon, 13 Jan 2025 00:00:00 GMT | POLYGON ((-79.25882 36.17252, -79.25959 36.133... |
| 1 | 2 | Alexander | 003 | Recorded survey data is available. Visit North... | https://ncem-gis.maps.arcgis.com/apps/webappvi... | Mon, 13 Jan 2025 00:00:00 GMT | POLYGON ((-81.10951 35.7766, -81.10973 35.7768... |
| 2 | 3 | Alleghany | 005 | No recent survey data available | Tue, 29 Nov 2011 00:00:00 GMT | POLYGON ((-81.25365 36.3666, -81.25325 36.3668... | |
| 3 | 4 | Anson | 007 | No recent survey data available | Tue, 29 Nov 2011 00:00:00 GMT | POLYGON ((-80.27683 35.19573, -80.27662 35.195... | |
| 4 | 5 | Ashe | 009 | Recorded survey data is available. Visit North... | https://ncem-gis.maps.arcgis.com/apps/webappvi... | Mon, 13 Jan 2025 00:00:00 GMT | POLYGON ((-81.47731 36.24026, -81.48632 36.241... |
Create a variable equal to the plot of nc_counties. This will serve as the base of our map. Format it to your taste.
Next, create a plot of the NC_Public_Schools data. You will need to you new variable into the ax parameter to serve as an Axes object. This allows what we just plotted to serve as the base of our map. If you want to adjust the markersize based on a variable, simply pass a column in from the dataset and each point will adjust in size according to the data in that column.
base = nc_counties.plot(color='lightblue', edgecolor='black', figsize=(32,32))
nc_public_schools.plot(ax = base, color='darkblue', markersize=nc_public_schools['num_teach'])
<Axes: >