
Created by Nathan Kelber and Ted Lawless for JSTOR Labs under Creative Commons CC BY License
For questions/comments/improvements, email nathan.kelber@ithaka.org.
Python Intermediate 2#
Description: This notebook describes how to:
Read and write files (.txt, .csv, .json)
Use the
constellateclient to read in metadataUse the
constellateclient to read in data
This notebook describes how to read and write text, CSV, and JSON files using Python. Additionally, it explains how the constellate client can help users easily load and analyze their datasets.
Use Case: For Learners (Detailed explanation, not ideal for researchers)
Difficulty: Intermediate
Completion Time: 90 minutes
Knowledge Required:
Python Basics (Start Python Basics I)
Knowledge Recommended:
Data Format: Text (.txt), CSV (.csv), JSON (.json)
Libraries Used:
pandas to read and write CSV files
jsonto read and write JSON filesconstellate client to retrieve and read data
Research Pipeline: None
### Download Sample Files for this Lesson
import urllib.request
from pathlib import Path
# Check if a data folder exists. If not, create it.
data_folder = Path('../data/')
data_folder.mkdir(exist_ok=True)
download_urls = [
'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/sample.csv',
'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/sample.txt',
'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/adaptation.txt'
]
for url in download_urls:
urllib.request.urlretrieve(url, '../data/' + url.rsplit('/', 1)[-1])
print('Sample files ready.')
Sample files ready.
Files in Python#
Working with files is an essential part of Python programming. When we execute code in Python, we manipulate data through the use of variables. When the program is closed, however, any data stored in those variables is erased. To save the information stored in variables, we must learn how to write it to a file.
At the same time, we may have notebooks for applying specific analyses, but we need to have a way to bring data into the notebook for analysis. Otherwise, we would have to type all the data into the program ourselves! Both reading-in from files and writing-out data to files are important skills for data science and the digital humanities.
This section describes how to work with three kinds of common data files in Python:
Plain Text Files (.txt)
Comma-Separated Value files (.csv)
Javascript Object Notation files (.json)
Each of these filetypes are in wide use in data science, digital humanities, and general programming.
Three Common Data File Types#
Plain Text Files (.txt)#
A plain text file is one of the simplest kinds of computer files. Plain text files can be opened with a text editor like Notepad (Windows 10) or TextEdit (OS X). The file can contain only basic textual characters such as: letters, numbers, spaces, and line breaks. Plain text files do not contain styling such as: heading sizes, italic, bold, or specialized fonts. (To including styling in a text file, writers may use other file formats such as rich text format (.rtf) or markdown (.md).)
Plain text files (.txt) can be easily viewed and modified by humans by changing the text within. This is an important distinction from binary files such as images (.jpg), archives (.gzip), audio (.wav), or video (.mp4). If a binary file is opened with a text editor, the content will be largely unreadable.
Comma-Separated Value Files (.csv)#
A comma-separated value file is also a text file that can easily be modifed with a text editor. A CSV file is generally used to store data that fits in a series or table (like a list or spreadsheet). A spreadsheet application (like Microsoft Excel or Google Sheets) will allow you to view and edit a CSV data in the form of a table.
Each row of a CSV file represents a single row of a table. The values in a CSV are separated by commas (with no space between), but other delimiters can be chosen such as a tab or pipe (|). A tab-separated value file is called a TSV file (.tsv). Using tabs or pipes may be preferable if the data being stored contains commas (since this could make it confusing whether a comma is part of a single entry or a delimiter between entries).
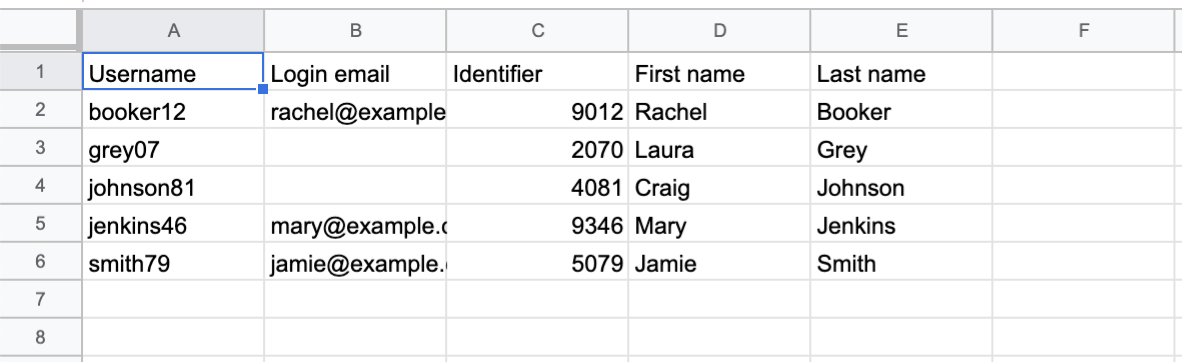
The text contents of a sample CSV file#
Username,Login email,Identifier,First name,Last name
booker12,rachel@example.com,9012,Rachel,Booker
grey07,,2070,Laura,Grey
johnson81,,4081,Craig,Johnson
jenkins46,mary@example.com,9346,Mary,Jenkins
smith79,jamie@example.com,5079,Jamie,Smith
The same CSV file represented in Google Sheets:#
JavaScript Object Notation (.json)#
A Javascript Object Notation file is also a text file that can be modified with a text editor. A JSON file stores data in key/value pairs, very similar to a Python dictionary. One of the key benefits of JSON is its compactness which makes it ideal for exchanging data between web browsers and servers.
While smaller JSON files can be opened in a text editor, larger files can be difficult to read. Viewing and editing JSON is easier in specialized editors, available online at sites like:
A JSON file has a nested structure, where smaller concepts are grouped under larger ones. Like extensible markup language (.xml), a JSON file can be checked to determine that it is valid (follows the proper format for JSON) and/or well-formed (follows the proper format defined in a specialized example, called a schema).
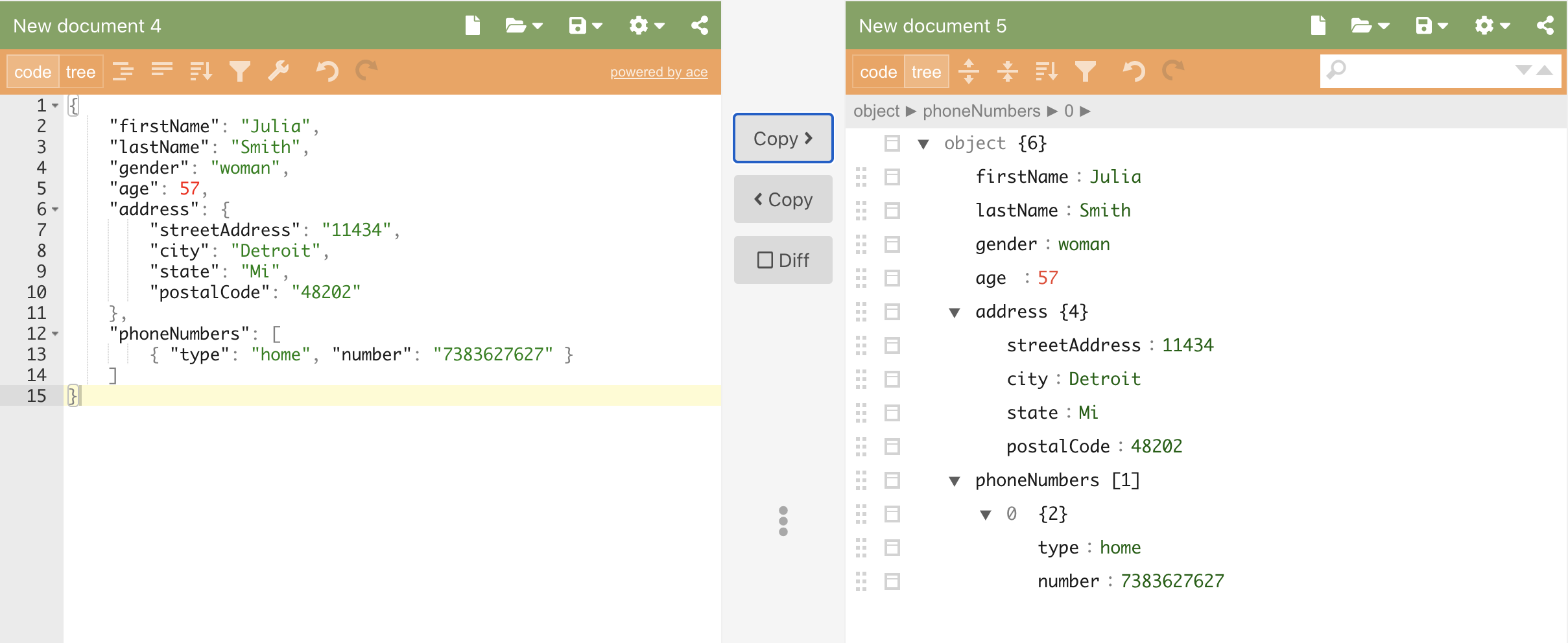
The text contents of a sample JSON file#
{
"firstName": "Julia",
"lastName": "Smith",
"gender": "woman",
"age": 57,
"address": {
"streetAddress": "11434",
"city": "Detroit",
"state": "Mi",
"postalCode": "48202"
},
"phoneNumbers": [
{ "type": "home", "number": "7383627627" }
]
}
The same JSON file represented in JSON Editor Online#
Opening, Reading, and Writing Text Files (.txt)#
Before we can read or write to a text file, we must open the file. Normally, when we open a file, a new window appears where we can see the file contents. In Python, opening a file means creating a file object that references the particular file. When the file has been opened, we can read or write to the file using the file object. Finally, we must close the file. Here are the three steps:
Open the file using
with open()using readr, writew, read+writer+or appendamodeUse the
.read()or.write()method on the file objectLet the code block close which automatically closes the file
Let’s practice on sample.txt, a sample text file.
# Opening a file in read mode
with open('../data/sample.txt', 'r') as f:
print(f.read())
A text file can have many words in it
These words are written on the second line
Third line
Fourth line
Fifth line
Sixth line
Seventh line
Eighth line
Ninth line
Tenth line. This is the end of the text file!
We have created a file object called f. The first argument ('data/sample.txt') passed into the open() function is a string containing the file name. You can see the sample.txt is in the data directory in the file browser to the left. If your file was called reports.txt, you would replace that argument with 'data/reports.txt'. The second argument ('r') determines that we are opening the file in “read” mode, where the file can be read but not modified. There are four main modes that can be specified when creating a file object:
Argument |
Mode Name |
Description |
|---|---|---|
‘r’ |
read |
Reads file but no writing allowed (protects file from modification) |
‘w’ |
write |
Writes to file, overwriting any information in the file (saves over the current version of the file) |
‘r+’ |
read+write |
Makes the file object available for both reading and writing. |
‘a’ |
append |
Appends (or adds) information to the end of the file (new information is added below old information) |
Reading Very Large Text Files (Line by Line)#
If the file is very large, we may want to read it one line at a time. To read a single line at a time, we can use a for loop instead of the .read() method. This is useful when you are working with large files that approach the amount of memory in your computer. This depends on your computer, but is probably about 8 GB or larger. (In a plain text file, that would be roughly 5.5 million pages.)
# Opening a file in read mode
with open('../data/sample.txt', 'r') as f:
for line in f:
print(line, end='') # By default each print inserts a line break, pass `end = ''` to remove this break
A text file can have many words in it
These words are written on the second line
Third line
Fourth line
Fifth line
Sixth line
Seventh line
Eighth line
Ninth line
Tenth line. This is the end of the text file!
Coding Challenge! < / >
In the data folder is a poem called Adaptation by the 2022 American Poet Laureate, Ada Limón. The file is called adaptation.txt. Open the file and print it out line by line.
For a more difficult challenge, print the title and author before the poem along with a number for each line.
# Read and print the poem found in /data/adaptation.txt
# Print the title and author before the poem along with a number for each line
Chunking file reading with .read()#
We can also read large files in chunks using .read() passing an argument that specifies the number of bytes to read in each chunk.
# Reading a set number of bytes with .read()
with open('../data/sample.txt', 'r') as f:
while True:
file_chunk = f.read(4) # Try changing the argument here
if len(file_chunk) > 0:
print(file_chunk)
else:
break
A te
xt f
ile
can
have
man
y wo
rds
in i
t
Th
ese
word
s ar
e wr
itte
n on
the
sec
ond
line
Thi
rd l
ine
Four
th l
ine
Fift
h li
ne
S
ixth
lin
e
Se
vent
h li
ne
E
ight
h li
ne
N
inth
lin
e
Te
nth
line
. Th
is i
s th
e en
d of
the
tex
t fi
le!
Writing to and Creating Files with .write()#
The .write() method can be used with a file opened in write mode (‘w’), read+write mode (‘r+), or append mode (‘a’). If you try to use the .write() method on a file opened in read mode (‘r’), the write will fail and you will get a “not writable” error.
# Trying to use `.write()` on a file in read mode
# will create an error
with open('../data/sample.txt', 'r') as f:
f.write('Add this text to the file')
---------------------------------------------------------------------------
UnsupportedOperation Traceback (most recent call last)
Cell In[5], line 5
1 # Trying to use `.write()` on a file in read mode
2 # will create an error
4 with open('../data/sample.txt', 'r') as f:
----> 5 f.write('Add this text to the file')
UnsupportedOperation: not writable
If you want to use the .write() method to write to a file, we demonstrate three common modes here: write (‘w’), read+write (‘r+’) and append (‘a’) mode.
Choose write mode (‘w’) if:
You want to create a new text file and/or write data to it
You want to overwrite all data in the file
Be careful with write mode, since it will write over any existing file!
Choose read+write mode (‘r+’) if:
You need to both read and write data to a file
You are okay overwriting the file if it already exists
You want the file pointer at the beginning of the file
Again, be careful with read+write mode (‘r+’) because it can overwrite existing data.
Choose append mode (‘a’) if:
You simply need to add more data to a file
You want to protect existing data in the file from being overwritten
There are also additional modes for working with a text file:
Mode |
Effect |
|---|---|
w |
Opens a file for writing only. Overwrites the file if the file exists. If the file does not exist, creates a new file for writing. |
r+ |
Opens a file for both reading and writing. The file pointer will be at the beginning of the file. |
a |
Opens a file for appending. The file pointer is at the end of the file if the file exists. That is, the file is in the append mode. If the file does not exist, it creates a new file for writing. |
w+ |
Opens a file for both writing and reading. Overwrites the existing file if the file exists. If the file does not exist, it creates a new file for reading and writing. |
a+ |
Opens a file for both appending and reading. The file pointer is at the end of the file if the file exists. The file opens in the append mode. If the file does not exist, it creates a new file for reading and writing. |
Create a new file using .write() method and write mode (‘w’)#
To create a new file, open a new file object in write mode. You may then use the .write() method to add some initial data to the file.
# Create a new file and write a string to the file
with open('../data/sample_new.txt', 'w') as f:
f.write('Put this string into the new file. ')
Modifying an existing file with using .write() method and read+write mode (‘r+’)#
You can read and write to the same file by opening it in read+write mode (‘r+’).
Coding Challenge! < / >
Open our sample_new.txt file, overwrite the word ‘Put’, the first three characters, with ‘Add’.
# Reading and writing to a file using read+write mode
with open('../data/sample_new.txt', 'r+') as f:
f.write('Add')
Appending to an existing file using .write() method and append mode (‘a’)#
Use the append mode if you want to be sure to preserve existing data in the file. Try appending some text onto the end of a file using append mode (‘a’).
Coding Challenge! < / >
Open our sample_new.txt file again. Add a second sentence to the file without overwriting the current file contents.
# Appending to a file using the append mode ('a')
Opening, Reading, and Writing CSV Files (.csv)#
CSV file data can be easily opened, read, and written using the pandas library. (For large CSV files (>500 mb), you may wish to use the csv library to read in a single row at a time to reduce the memory footprint.) Pandas is flexible for working with tabular data, and the process for importing and exporting to CSV is simple.
# Import pandas
import pandas as pd
# Create our dataframe
df = pd.read_csv('../data/sample.csv')
# Display the dataframe
print(df)
Username Login email Identifier First name Last name
0 booker12 rachel@example.com 9012 Rachel Booker
1 grey07 NaN 2070 Laura Grey
2 johnson81 NaN 4081 Craig Johnson
3 jenkins46 mary@example.com 9346 Mary Jenkins
4 smith79 jamie@example.com 5079 Jamie Smith
After you’ve made any necessary changes in Pandas, write the dataframe back to the CSV file. (Remember to always back up your data before writing over the file.)
# Write data to new file
# Keeping the Header but removing the index
df.to_csv('../data/new_sample.csv', header=True, index=False)
Opening, Reading, and Writing JSON Files (.json)#
JSON files use a key/value structure very similar to a Python dictionary. We will start with a Python dictionary called py_dict and then write the data to a JSON file using the json library.
# Defining sample data in a Python dictionary
py_dict = {
"firstName": "Julia",
"lastName": "Smith",
"gender": "woman",
"age": 57,
"address": {
"streetAddress": "11434",
"city": "Detroit",
"state": "Mi",
"postalCode": "48202"
},
"phoneNumber": "3133627627"
}
To write our dictionary to a JSON file, we will use the with open technique we learned that automatically closes file objects. We also need the json library to help dump our dictionary data into the file object. The json.dump function works a little differently than the write method we saw with text files.
We need to specify two arguments:
The data to be dumped
The file object where we are dumping
# Open/create sample.json in write mode
# as the file object `f`. The data in py_dict
# is dumped into `f` and then `f` is closed
import json
with open('../data/sample.json', 'w') as f:
json.dump(py_dict, f)
To read data in from a JSON file, we can use the json.load function on our file object. Here we load all the content into a variable called content. We can then print values based on particular keys.
# Open the .json file in read mode
# and print the loaded contents
with open('../data/sample.json', 'r') as f:
print(json.load(f))
{'firstName': 'Julia', 'lastName': 'Smith', 'gender': 'woman', 'age': 57, 'address': {'streetAddress': '11434', 'city': 'Detroit', 'state': 'Mi', 'postalCode': '48202'}, 'phoneNumber': '3133627627'}
# Load the current data from the file into a dictionary
# and add an entry to the dictionary
with open('../data/sample.json', 'r') as f:
file_contents = json.load(f)
file_contents['pet'] = 'dog'
# Write the contents of the dictionary over the existing data
with open('../data/sample.json', 'w') as f:
json.dump(file_contents, f)
The .load() method creates a Python dictionary from the .json file object. This means that we can query a particular key/value pair after loading the data.
# Load the data from the json file into a dictionary
# Check to see if there is value associated with pet
with open('../data/sample.json', 'r') as f:
json_contents = json.load(f)
print(json_contents.get('pet'))
dog
Coding Challenge! < / >
Add an entry to Julia Smith that indicates her favorite ice cream is chocolate peanut butter.
# Add an ice cream entry to Julia Smith's record
Opening datasets with constellate client#
The constellate client helps retrieve a given dataset and/or its associated metadata. The metadata is supplied in a CSV file and the full dataset is supplied in a compressed JSON Lines file (.jsonl.gz). For analysis focused on metadata, we recommend users start with the CSV file since it is both easier and faster to view, parse, and manipulate. If you need access to n-grams or full-text, then you want the full JSON lines file.
Metadata CSV vs. JSON Lines Data File#
All of the textual data and metadata is available inside of the JSON Lines files, but we have chosen to offer the metadata CSV for two primary reasons:
The JSON Lines data is a little more complex to parse since it is nested. It cannot be easily represented in a table form in something like Pandas. It is nice to be able to easily view all the metadata in a Pandas dataframe.
The JSON Lines data can be very large. Each file contains all of the metadata plus unigram counts, bigram counts, trigram counts, and full-text (when available). Manipulating all that data takes significant computer time and costs. Even a modest dataset (~5000 files) can be over 1 GB in size uncompressed.
More information is available, including the metadata categories, in the FAQ “What is the data file format?”. There’s also reference documentation for the constellate client.
Retrieving sampled data (constellate client methods)#
By passing the constellate client a dataset ID (here called dataset_id), we can automatically download the metadata CSV file or the full JSON Lines dataset created by the dataset builder. By default, these datasets are randomly sampled to 1500 documents. Experience has shown us that this is the right size for teaching/learning where data loads quickly and still gives interesting results.
Use the
.get_metadata()method to retrieve the sampled metadata CSV fileUse the
.get_dataset()method to retrieve the sampled JSON data file
Code |
Result |
|---|---|
f = constellate.get_metadata(dataset_id) |
Automatically retrieves a sampled metadata CSV file and creates a file object |
f = constellate.get_dataset(dataset_id) |
Automatically retrieves a sampled, compressed JSON Lines dataset file (jsonl.gz) and creates a file object |
The JSON Lines file will be downloaded in a compressed gzip format (jsonl.gz). We can iterate over each document in the corpus by using the dataset_reader() method.
# Downloading and reading a Constellate dataset
# If using locally, pip install constellate-client
import constellate
# Setting a dataset ID based on the journal Shakespeare Quarterly.
dataset_id = "2880ef54-b3b5-c0af-2ef1-ad557f236b5e"
# Pull in our dataset CSV using
# The .get_metadata() method downloads the CSV file for our metadata
# to the /data folder and returns a string for the file name and location
# dataset_metadata will be a string containing that file name and location
dataset_metadata = constellate.get_metadata(dataset_id)
# Pull in the sampled dataset (1500 documents) that matches `dataset_id`
# in the form of a gzipped JSON lines file.
# The .get_dataset() method downloads the gzipped JSONL file
# to the /data folder and returns a string for the file name and location
dataset_file = constellate.get_dataset(dataset_id)
Retrieving the full dataset with constellate client#
Researchers wishing to work with larger datasets (up to 25,000 items), first need to request these datasets be built.
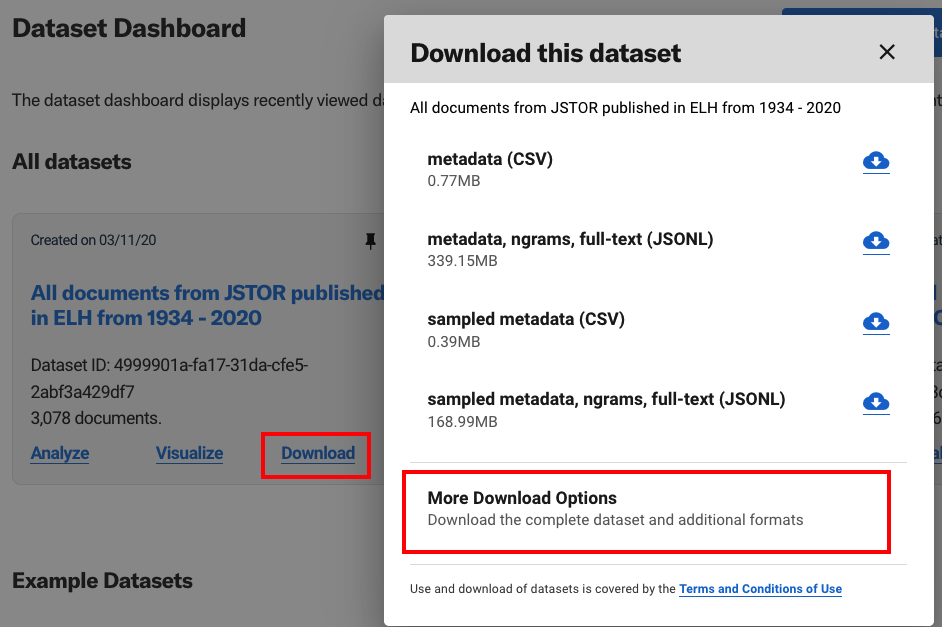
Then you can request the full dataset using the constellate.download method. For more information, see the Constellate Client reference documentation.
Code |
Result |
|---|---|
f = constellate.download(dataset_id, ‘metadata’) |
Automatically retrieves a full metadata CSV file and creates a file object |
f = constellate.download(dataset_id, ‘jsonl’) |
Automatically retrieves the full compressed JSON Lines dataset file (jsonl.gz) and creates a file object |
# To download the full dataset metadata (up to a limit of 25,000 documents),
# request it first in the builder environment. See the Constellate Client
# documentation at: https://constellate.org/docs/constellate-client
# Then use the `constellate.download` method show below.
dataset_metadata = constellate.download(dataset_id, 'metadata')
# To download the full dataset (up to a limit of 25,000 documents),
# request it first in the builder environment. See the Constellate Client
# documentation at: https://constellate.org/docs/constellate-client
# Then use the `constellate.download` method show below.
dataset_file = constellate.download(dataset_id, 'jsonl')
If you would like to work with a CSV file, pass the file object into Pandas read_csv function.
# Create a pandas dataframe from a metadata CSV file
import pandas as pd
# Create our dataframe
df = pd.read_csv(dataset_metadata)
# Preview our dataframe
df.head()
Reading in data from a dataset object#
When working with a Constellate JSON file, it is best to iterate over each line (representing all the data for a given document) using the dataset_reader method and a for loop.
The dataset_reader() method will read in data from the compressed JSON dataset file object. By keeping the data in a compressed format and reading in a single line at a time, we reduce the processing time and memory use. These can be substantial for large datasets.
The dataset_reader() essentially unzips each row/document and loads it into a dictionary. Each dictionary will contain all the metadata and data available for the current document.
In practice, that looks like:
Code |
Result |
|---|---|
for document in constellate.dataset_reader(dataset_file): |
Load all the data for a document into a dictionary, one by one |
# Loop over every document in the dataset
# and print the title
for document in constellate.dataset_reader(dataset_file):
print(document['title'])
Lesson Complete#
Congratulations! You have completed Python Intermediate 2.
Start Next Lesson: Python Intermediate 3#
Exercise Solutions#
Here are a few solutions for exercises in this lesson.
# Read and print the poem found in /data/adaptation.txt
# Create a variable to store the line
line_number = 1
print('ADAPTATION')
print('Ada Limón\n')
with open('../data/adaptation.txt', 'r') as f:
for line in f:
print(line_number, line, end='')
line_number += 1
# Reading and writing to a file using read+write mode ('r+')
with open('../data/sample_new.txt', 'r+') as f:
f.write('Add')
# Appending to a file using the append mode ('a')
with open('../data/sample_new.txt', 'a') as f:
f.write('A new sentence is added now.')
# Load the current data from the file into a dictionary
# and add an entry to the dictionary
with open('../data/sample.json', 'r') as f:
file_contents = json.load(f)
file_contents['favoriteIceCream'] = 'chocolate peanut butter'
# Write the contents of the dictionary over the existing data
with open('../data/sample.json', 'w') as f:
json.dump(file_contents, f)
with open('../data/sample.json', 'r') as f:
json_contents = json.load(f)
print(json_contents.get('favoriteIceCream'))