Introduction to Text Analysis in Python#
What is Text Analysis#
Text analysis, also known as text mining, is the process of extracting useful information and insights from written or spoken language. Text analysis involves using various computational techniques and algorithms to automatically process, classify, and analyze large amounts of text data. These techniques can include natural language processing, machine learning, and statistical analysis, among others. The goal of text analysis is to extract meaningful patterns, relationships, and insights from text data that can be used to inform decision-making or to gain a better understanding of a particular topic or issue. Some common applications of text analysis include sentiment analysis, topic modeling, text categorization, and text clustering. This notebook will go over some of the basic
In Python, the Natural Language Toolkit (NLTK) is a popular library for text processing and natural language processing tasks. NLTK provides several useful tools for tokenizing text, including word tokenization, sentence tokenization, and much more.
import nltk
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#nltk.download()
Tokenization#
String tokenization is the process of breaking down a string of text into smaller units called tokens. In natural language processing (NLP), these tokens are typically words or phrases that are separated by specific delimiters, such as spaces, punctuation marks, or special characters.
The process of tokenization is an important first step in many NLP applications, as it allows the text to be processed and analyzed more easily. Tokenization helps standardize text data by breaking it up into smaller, more manageable units. This makes it easier to compare and analyze different texts, as well as to develop algorithms and models that can process and understand text data. This also improves the computational efficiency of text analysis by reducing the size and complexity of the data. By breaking up a text document into smaller units, it becomes easier to process and analyze the data using algorithms and models.
Tokenization is also often a fundamental part of preprocessing data as it can help identify and remove unwanted characters, such as punctuation marks, and normalize words by converting them to a common case or stem. This allows for operations such as the frequency of certain tokens can be used as features in a text classification model, or the co-occurrence of certain tokens can be used to identify relationships between words or topics.
In this example, we first import the word tokenize sentence_tokenize function from the nltk.tokenize module. We then define a string sentence that we want to tokenize and call the sentence_tokenize function on it. The function returns a list of tokens, which we then print to the console.
from nltk.tokenize import sent_tokenize, word_tokenize, wordpunct_tokenize
text = """Hi there, how are you? I am doing well, thanks for asking. It is really nice out today!
Think it will rain tomorrow? The weather caster predicted a 40% chance of precipitation. Maybe, I will bring a jacket with me tomorrow just in case."""
sentence_tokens = sent_tokenize(text)
print("Sentence Tokens: " + str(sentence_tokens))
Sentence Tokens: ['Hi there, how are you?', 'I am doing well, thanks for asking.', 'It is really nice out today!', 'Think it will rain tomorrow?', 'The weather caster predicted a 40% chance of precipitation.', 'Maybe, I will bring a jacket with me tomorrow just in case.']
word_tokens = word_tokenize(text)
print("Word Tokens: " + str(word_tokens))
Word Tokens: ['Hi', 'there', ',', 'how', 'are', 'you', '?', 'I', 'am', 'doing', 'well', ',', 'thanks', 'for', 'asking', '.', 'It', 'is', 'really', 'nice', 'out', 'today', '!', 'Think', 'it', 'will', 'rain', 'tomorrow', '?', 'The', 'weather', 'caster', 'predicted', 'a', '40', '%', 'chance', 'of', 'precipitation', '.', 'Maybe', ',', 'I', 'will', 'bring', 'a', 'jacket', 'with', 'me', 'tomorrow', 'just', 'in', 'case', '.']
Frequency Distribution#
A frequency distribution is a statistical measure that shows how often each value or category occurs in a dataset. It is a way to summarize and analyze data by counting the number of times each observation or category appears in a dataset. Frequency distributions are commonly used in many different fields, including statistics, data analysis, and natural language processing.
In natural language processing, frequency distributions are often used to analyze the distribution of words or phrases in a text corpus. By counting the frequency of each word or phrase, it is possible to identify the most common words, determine the overall distribution of word usage, and identify patterns in the data.
Frequency distributions can be represented in various ways, such as histograms, bar charts, or tables. In Python, the FreqDist() method in the nltk library is commonly used to create and visualize frequency distributions of words or tokens in text data. In NLTK, a frequency distribution is a data structure that allows you to count the number of times that each element (e.g., words or tokens) appears in a text. You can create a frequency distribution using the FreqDist() method, which takes a list of tokens as input.
To create a frequency distribution from the list of tokens we created you first need to import FreqDist from nltk.probability. You can create a FreqDist object from the previously made list ‘word_tokens’ by creating a variable and setting it to ‘FreqDist(word_tokens).’ If you print the variable, it will only show you the number of samples and outcomes. If you want a list of the most common tokens in the list you can freq_dist.most_common(X) to get a list of the X most common tokens.
from nltk.probability import FreqDist
freq_dist = FreqDist(word_tokens)
print(freq_dist)
print("Most common tokens: " + str(freq_dist.most_common(5)))
<FreqDist with 45 samples and 54 outcomes>
Most common tokens: [(',', 3), ('.', 3), ('?', 2), ('I', 2), ('will', 2)]
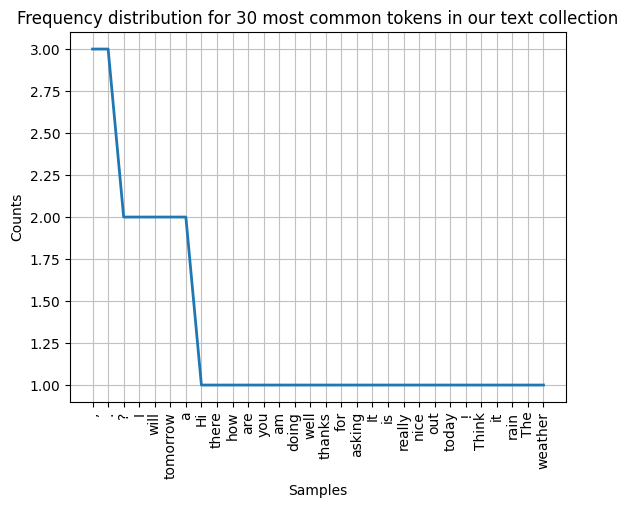
To plot a simple frequency distribution, all you have to do is call the plot() function on the your frequency distribution variable. The first parameter will take in a number to show the X most common tokens in the list.
freq_dist.plot(30, title='Frequency distribution for 30 most common tokens in our text collection')
plt.show()
Stopwords#
In natural language processing, stopwords are words that are commonly used in a language but do not carry significant meaning and are often removed from the text during preprocessing. Examples of stopwords in English include “the”, “and”, “a”, “an”, “in”, “of”, “to”, “is”, “for”, “that”, and so on.
Stopwords are often removed from text data during text preprocessing because they can negatively affect text analysis tasks such as topic modeling, sentiment analysis, and classification. This is because they occur frequently in text data but do not provide much useful information about the content of the text. Removing stopwords can help to reduce noise in the data and improve the accuracy of the analysis.
You can import a premade list of stopwords from nltk.corpus. You will have to specify the language you are wanting to find stopwords for. You can print the list to see the entirety of the stopwords.
from nltk.corpus import stopwords
stopwords = set(stopwords.words("english"))
print(stopwords)
{'so', 'few', 'had', 'out', 'in', 'itself', 'mustn', "she'd", "they're", 'hadn', 'under', 'too', 'their', 'does', 'been', "won't", "you're", 'he', 'and', 'mightn', 'all', "he'd", 'it', 'ourselves', 'shouldn', "we'd", 'yourselves', 'not', 'of', 'the', "haven't", 'nor', 'won', "he'll", "i've", 'these', 'yourself', 'him', "they'd", "it's", 't', "weren't", 'when', 'wasn', 'or', 'we', 'o', 'an', 'above', 'its', 'she', "shouldn't", 'why', 'doesn', 'is', "wasn't", 'are', 'before', 'can', 'if', 'some', 'through', 'doing', 'her', 'which', "isn't", 'now', 'because', 'themselves', 'd', 'up', 'haven', 'was', 'very', "it'd", 'between', 'during', "i'm", "mustn't", "don't", 'your', 'whom', 'isn', 'below', "they'll", 've', "he's", "you've", 'will', 'has', 'each', 'don', "shan't", 'weren', "mightn't", 'into', "wouldn't", 'have', 'only', 'were', 'who', 'while', "you'll", 'do', 'to', 'be', 'both', 'being', 'ours', "she'll", 'as', 'about', "hadn't", 'our', 'then', 'y', "doesn't", "couldn't", 'once', "needn't", 'how', "we'll", 'just', "we've", 'didn', "that'll", 'what', 'you', 'than', "she's", "aren't", 'them', 'from', 'any', 'ain', 'no', "didn't", 'over', 'shan', 'here', 'after', 'those', 'a', 'where', 'down', 'this', 'more', 'couldn', 'should', 'most', 's', 'such', 'they', 'myself', 'at', 'having', 'hasn', 'himself', 'my', "they've", 'ma', 'i', "we're", 'his', 'wouldn', 'same', 'there', 'with', 'again', 're', 'aren', 'am', 'hers', 'll', 'needn', 'that', 'theirs', 'other', "hasn't", 'against', 'me', "it'll", "you'd", 'for', 'yours', 'did', "should've", 'by', 'm', "i'd", 'own', "i'll", 'until', 'off', 'on', 'further', 'herself', 'but'}
To remove all stopwords from the list of tokens, you can start by making a new empty list. Loop through the list of word tokens, checking to see if each token is in the list of stopwords. Make sure to set i to lowercase when checking against the stopwords list. If i is not in stopwords, append it to the empty list.
stopwords_removed = []
for i in word_tokens:
if i.lower() not in stopwords:
stopwords_removed.append(i)
print("List of Word Tokens without Stopwords: " + str(stopwords_removed))
List of Word Tokens without Stopwords: ['Hi', ',', '?', 'well', ',', 'thanks', 'asking', '.', 'really', 'nice', 'today', '!', 'Think', 'rain', 'tomorrow', '?', 'weather', 'caster', 'predicted', '40', '%', 'chance', 'precipitation', '.', 'Maybe', ',', 'bring', 'jacket', 'tomorrow', 'case', '.']
If you don’t want punctuation in your list of tokens, you can do something similar to the above. This time you will want to import string. Instead of checking against stopwords, you will check if i is in string.punctuation. If it isn’t, append it to the new list.
For illustration purposes, this step and the last step were separated. Typically it is much better to combine these two steps. Can you figure out how to combine removing stop words and punctuation into one step?
import string
punct_removed = []
for i in stopwords_removed:
if i not in string.punctuation:
punct_removed.append(i)
print("List of Punctuation: " + str(string.punctuation))
print("List of Word Tokens without Stopwords: " + str(punct_removed))
List of Punctuation: !"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
List of Word Tokens without Stopwords: ['Hi', 'well', 'thanks', 'asking', 'really', 'nice', 'today', 'Think', 'rain', 'tomorrow', 'weather', 'caster', 'predicted', '40', 'chance', 'precipitation', 'Maybe', 'bring', 'jacket', 'tomorrow', 'case']
Stemming VS Lemmatization#
Stemming and lemmatization are two common techniques used in natural language processing to reduce words to their base or root form. The main difference between them is that stemming involves reducing a word to its base form by removing suffixes, while lemmatization involves reducing a word to its base form by considering the context and meaning of the word.
Stemming is a more basic technique than lemmatization and involves the process of removing suffixes from a word to obtain its base or root form. Stemming is often used to normalize words in text data, which can help to reduce the size of the vocabulary and improve the efficiency of text analysis tasks. Examples of stemming algorithms include the Porter Stemmer and Snowball Stemmer.
Lemmatization, on the other hand, involves reducing words to their base form based on their dictionary definition or part of speech. This technique takes into account the context and meaning of the word, and as a result, can produce better results than stemming. For example, the lemma of the word “running” is “run”, while the stem is “runn”. Lemmatization can be computationally expensive compared to stemming but can provide better accuracy in certain tasks such as information retrieval or question-answering systems.
To see the difference, go ahead and import PorterStemmer and WordNetLemmatizerfrom nltk.stem and initialize objects for both of them. Create two empty lists, one for stems and one for lemmas. Loop through the list of tokens and append their respective methods to get stem or lemma of i, ps.stem(i), and lm.lemmatize(i). Print both lists and see if you can spot the differences.
from nltk.stem import PorterStemmer, WordNetLemmatizer
ps = PorterStemmer()
stems = []
lm = WordNetLemmatizer()
lem = []
for i in punct_removed:
stems.append(ps.stem(i))
lem.append(lm.lemmatize(i))
print("Stems: " + str(stems))
print("Lemmatization: " + str(lem))
Stems: ['hi', 'well', 'thank', 'ask', 'realli', 'nice', 'today', 'think', 'rain', 'tomorrow', 'weather', 'caster', 'predict', '40', 'chanc', 'precipit', 'mayb', 'bring', 'jacket', 'tomorrow', 'case']
Lemmatization: ['Hi', 'well', 'thanks', 'asking', 'really', 'nice', 'today', 'Think', 'rain', 'tomorrow', 'weather', 'caster', 'predicted', '40', 'chance', 'precipitation', 'Maybe', 'bring', 'jacket', 'tomorrow', 'case']
Working with Real Data#
Now it’s time to work with a larger, real-world set of data. For this example, we will be using a text file containing “Alice in Wonderland” by Lewis Carroll. This was found on the website Project Gutenberg. If you want to use something different feel free to browse there or elsewhere. Be sure to remove the information from the Gutenberg Press from both the beginning and the end of the text file before you start.
Set a variable equal to the path where you stored the file and open it with the open function. Use the with keyword to automatically close the file when you are done parsing it. Be sure to set the encoding to ‘utf8’ otherwise you will run into errors.
path = '../Data_Visualization/alice_in_wonderland.txt'
with open(path, encoding='utf8') as f:
alice = f.read()
Tokenize and clean the file you just read in a similar way to the steps we used above. This time we will go ahead and remove stopwords and punctuation in one loop. Create a FreqDist from the new list and go ahead and print the most common tokens.
alice_words = word_tokenize(alice)
alice_cleaned = []
for i in alice_words:
if i.lower() not in stopwords and i not in string.punctuation:
alice_cleaned.append(lm.lemmatize(i))
alice_freq_dist = FreqDist(alice_cleaned)
print("Most common tokens:" + str(alice_freq_dist.most_common(30)))
Most common tokens:[('“', 1118), ('”', 1114), ('’', 706), ('said', 453), ('Alice', 397), ('little', 125), ('one', 94), ('went', 83), ('like', 83), ('thought', 76), ('thing', 76), ('Queen', 75), ('could', 74), ('know', 74), ('would', 70), ('time', 70), ('see', 64), ('King', 61), ('Mock', 57), ('Turtle', 57), ('began', 57), ('head', 57), ('Hatter', 55), ('Gryphon', 55), ('go', 54), ('quite', 53), ('way', 52), ('say', 52), ('much', 51), ('voice', 49)]
You might notice that the first three most common tokens are punctuation that wasn’t contained in the punctuation list. To fix this we will have to add them as extra conditions in our if statement as seen below.
alice_cleaned = []
for i in alice_words:
if i.lower() not in stopwords and i not in string.punctuation and i != '“' and i != '”' and i != '’':
alice_cleaned.append(lm.lemmatize(i))
alice_freq_dist = FreqDist(alice_cleaned)
print("Most common tokens:" + str(alice_freq_dist.most_common(30)))
Most common tokens:[('said', 453), ('Alice', 397), ('little', 125), ('one', 94), ('went', 83), ('like', 83), ('thought', 76), ('thing', 76), ('Queen', 75), ('could', 74), ('know', 74), ('would', 70), ('time', 70), ('see', 64), ('King', 61), ('Mock', 57), ('Turtle', 57), ('began', 57), ('head', 57), ('Hatter', 55), ('Gryphon', 55), ('go', 54), ('quite', 53), ('way', 52), ('say', 52), ('much', 51), ('voice', 49), ('‘', 46), ('Rabbit', 45), ('think', 45)]
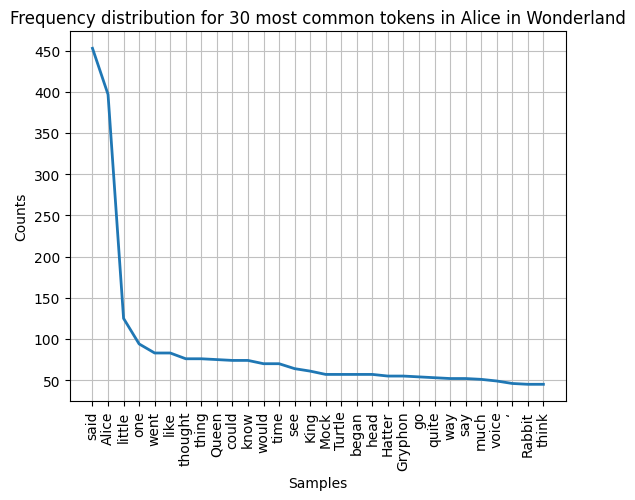
Go ahead and plot a frequency distrobution of the tokens.
alice_freq_dist.plot(30, title='Frequency distribution for 30 most common tokens in Alice in Wonderland')
plt.show()
Now lets do something a little extra and make a word cloud out of our tokens. A word cloud, also known as a tag cloud or wordle, is a visual representation of text data in which the size of each word indicates its frequency or importance in the text. Word clouds are often used to provide a quick overview or summary of text data and to identify the most common or relevant words in a document, website, or other sources of textual information.
In a word cloud, each word is represented by a font size that is proportional to its frequency in the text. The most frequent words appear larger and are usually positioned toward the center of the cloud, while less frequent words appear smaller and are positioned toward the edges. The words are usually presented in different colors and fonts to make the cloud more visually appealing and easy to read.
To create a WordCloud go ahead and import WordCloud from wordcloud. Set variable equal to a WordCloud object using the generate function on your text. Adjust the size of the figure using the figure() function. You will need to use the imshow() function to render the WordCloud object as an image. You will want to set the axis to off, so you don’t see numbers alongside your image. Finally, show your WordCloud with the show() function.
from wordcloud import WordCloud
import numpy as np
alice_word_cloud = WordCloud(background_color = 'black', max_words = 500).generate(str(alice_cleaned))
plt.figure(figsize =(18,10))
plt.imshow(alice_word_cloud)
plt.axis('off')
plt.show()

You can also add a mask to change the shape of your WordCloud. Create a numpy array from an image of your choice as below. Set the mask parameter equal to your array. Be sure to find an image that is mostly solid and simple in shape so it is fairly obvious what the word cloud is supposed to be.
from wordcloud import WordCloud
import numpy as np
mask = np.array(Image.open('top_hat.png'))
alice_word_cloud = WordCloud(mask = mask, background_color = 'black', max_words = 500).generate(str(alice_cleaned))
plt.figure(figsize =(18,10))
plt.imshow(alice_word_cloud)
plt.axis('off')
plt.savefig("wordcloud_top_hat.png")
plt.show()

Acknowledgments#
This notebook includes contributions and insights from Patrick Wolfe, MLIS graduate, 2023.