This notebook was created by William Mattingly for the 2022 Text Analysis Pedagogy Institute, with support from the National Endowment for the Humanities, JSTOR Labs, and University of Arizona Libraries.
This notebook is adapted by Zhuo Chen under Creative Commons CC BY License.
For questions/comments/improvements, email zhuo.chen@ithaka.org or nathan.kelber@ithaka.org.
MultiLingual NER#
This is lesson 1 of 3 in the educational series on Named Entity Recognition. This notebook is intended to show the basic problems one faces in multilingual texts.
Description: This notebook describes how to:
Understand Named Entity Recognition (NER) as a concept
Understand text encoding
Understand how to solve encoding-issues
Understand the complexities of multilingual corpora
Use case: For Learners (Detailed explanation, not ideal for researchers)
Difficulty: Intermediate
Completion time: 90 minutes
Knowledge Required:
Python basics (start learning Python basics)
Knowledge Recommended:
Natural Language Processing
Data Format: .txt
Libraries Used: spaCy
Research Pipeline: None
Introduction to Named Entity Recognition#
Named Entity Recognition#
Entities are words in a text that correspond to a specific type of data. For example, we may find the following types of entities in a text.
numerical, such as cardinal numbers;
temporal, such as dates;
nominal, such as names of people and places;
political, such as geopolitical entities (GPE).
Named entity recognition, or NER, is the process by which a system takes an input of a text and outputs the identification of entities.
A simple example#
Let’s use the following sentence as an example.
Martha, a senior, moved to Spain where she will be playing basketball until 05 June 2022 or until she can’t play any longer.
First, there is “Martha”, a person’s name. Different NER models may give the label of PERSON or PER to it.
Second, there is “Spain”, a country name. It is a GPE, or Geopolitical Entity.
Finally, there is “05 June 2022”, a date. It is a DATE entity.
In this series, we are going to use the SpaCy library to do NER. Here is a preview of how spaCy identifies entities in a text string.
# Install required library spacy
!pip3 install spacy # Install spacy
# download the small English NLP model from spacy
!python3 -m spacy download en_core_web_sm # for English NER
# import spacy
import spacy
# load the small English model
nlp = spacy.load("en_core_web_sm")
# Create a doc object out of the text string
sentence = """Martha, a senior, moved to Spain where she will be playing basketball until 05 June 2022
or until she can't play any longer."""
doc = nlp(sentence)
# Get the entities from the doc
for ent in doc.ents:
print(ent.text, ent.label_)
Natural Language Processing#
Natual Language Processing (NLP) is the process by which a researcher uses a computer system to parse human language and extract important information from texts.
How do we extract information from texts? We do it through a series of pipelines that perform some operations on the data at hand.
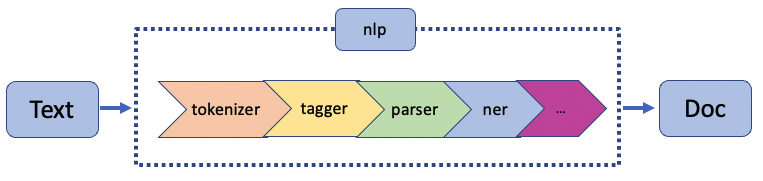
Named entity recognition is a branch of natural language processing. From the graph, you may notice that named entity recognition comes later in NLP. This is because it needs to receive a tokenized text and, in some languages, it needs to understand a word’s part-of-speech (POS) to perform well.
Tokenizer#
The job of a tokenizer is to break a text into individual tokens. Tokens are items in a text that have some linguistic meaning. They can be words, such as “Martha”, but they can also be punctuation marks, such as “,” in the relative clause “, a senior,”. Likewise, “n’t” in the contraction “can’t” would also be recognized as a token since “n’t” in English corresponds to the word “not”.
# Get the tokens in the doc object we created
for token in doc:
print(token.text)
POS tagger#
A common pipeline after a tokenizer is a POS tagger whose job is to identify the parts-of-speech, or POS, in the text. Let us consider an example sentence:
The boy took the ball to the store.
The nominative (subject), “boy”, comes first in the sentence, followed by the verb, “took”, then followed by the accusative (object), “ball”, and finally the dative (indirect object), “store”. The words “the” and “to” also contain vital information. “The” occurs twice and tells the reader that it’s not just any ball, it’s the ball; likewise, it’s not just a store, but the store. The period too tells us something important. This is a statement, not a question.
# Import the visualizer in spaCy
from spacy import displacy
# Visualize the POS tags and syntactic dependencies using displacy.serve() function
displacy.render(doc, style="dep")
# Get all pos tags
dir(spacy.parts_of_speech)
# Get the meaning of a certain tag
spacy.explain('PROPN')
Text Encoding#
Before we tokenize a text, we have to know what encoding it uses.
When we say “plain text”, we are actually being really sloppy. There is no such thing as “plain text”! It does not make sense to have a text without knowing what encoding it uses.
Have you ever received an email in which you find the text is unintelligible because there are random question marks in it? Did you wonder why?
A little bit history about text encoding#
ASCII (American Standard Code for Information Interchange)#
There was an old time when the only characters that mattered were good old unaccented English letters. ASCII is a code which was able to represent every character using a number between 32 and 127 (Codes below 32 were called unprintable and for control characters, e.g. the backspace). For example, the ASCII code of the letter A is 65. As you know, computers use a binary system and therefore the number 65 is actually encoded as a 8-bit number.
A \(\rightarrow\) 0100 0001
8-bit allows up to \(2^{8}=256\) characters and we have only had 128 (with numbers 0-127). That means we can use the numbers 128 to 255 to represent other characters! English, of course, is not the only language that matters. Therefore, people speaking different languages chose to use the numbers 128 to 255 for the characters in their own language. This means that two different characters from two different languages may be represented by the same number in their respective encoding standard. This is no good, because when Americans would send their résumés to Israel they would arrive as rגsumגs.
UTF-8#
Can’t we have a single character set that includes every reasonable writing system on the planet? Yes we can! Here comes the brilliant idea of UTF-8. UTF stands for Unicode Tranformation Format. 8 means 8-bit.
Every letter in every alphabet is assigned a number written like this: U+0041. It is called a code point. The U+ means “Unicode” and the numbers are hexadecimal. In Python, code points are written in the form \uXXXX, where XXXX is the number in 4-digit hexadecimal form. The English letter A is assigned the number U+0041.
UTF-8 was designed for backward compatibility with ASCII: the first 128 characters of Unicode, which correspond one-to-one with ASCII, are encoded using a single byte with the same binary value as ASCII.
ord( ) and chr( )#
ord() and chr() are built-in functions in Python.
The ord() function takes a single Unicode character and returns its integer Unicode code point value.
# Use ord() to convert a Unicode character string to its integer code point value
ord("ø")
The chr() function does the opposite. It takes an integer and returns the corresponding Unicode character.
# Use chr() to convert a number to a character
chr(248)
The brief historical review gives us an idea of how messy it was with regard to text encoding before UTF-8. There were and actually still are so many different encoding methods out there. Right now I am viewing a webpage in Safari. I can take a peek at how many different encoding methods there are by just choosing View > Text Encoding. For you, depending on your browser, you may find the text encoding in a different place.
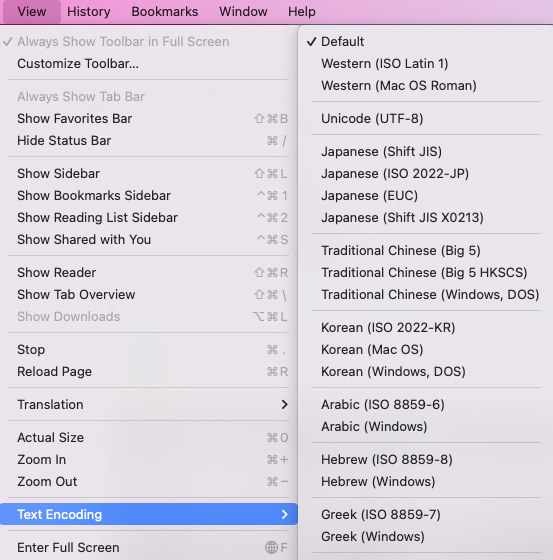
Coding Challenge! < / >
Go to a website of your choice. Change the text encoding of the page to a different one. What happens after you change the encoding? Keep changing the text encoding to different encoding methods and see what happens. Last, change the text encoding to utf8.
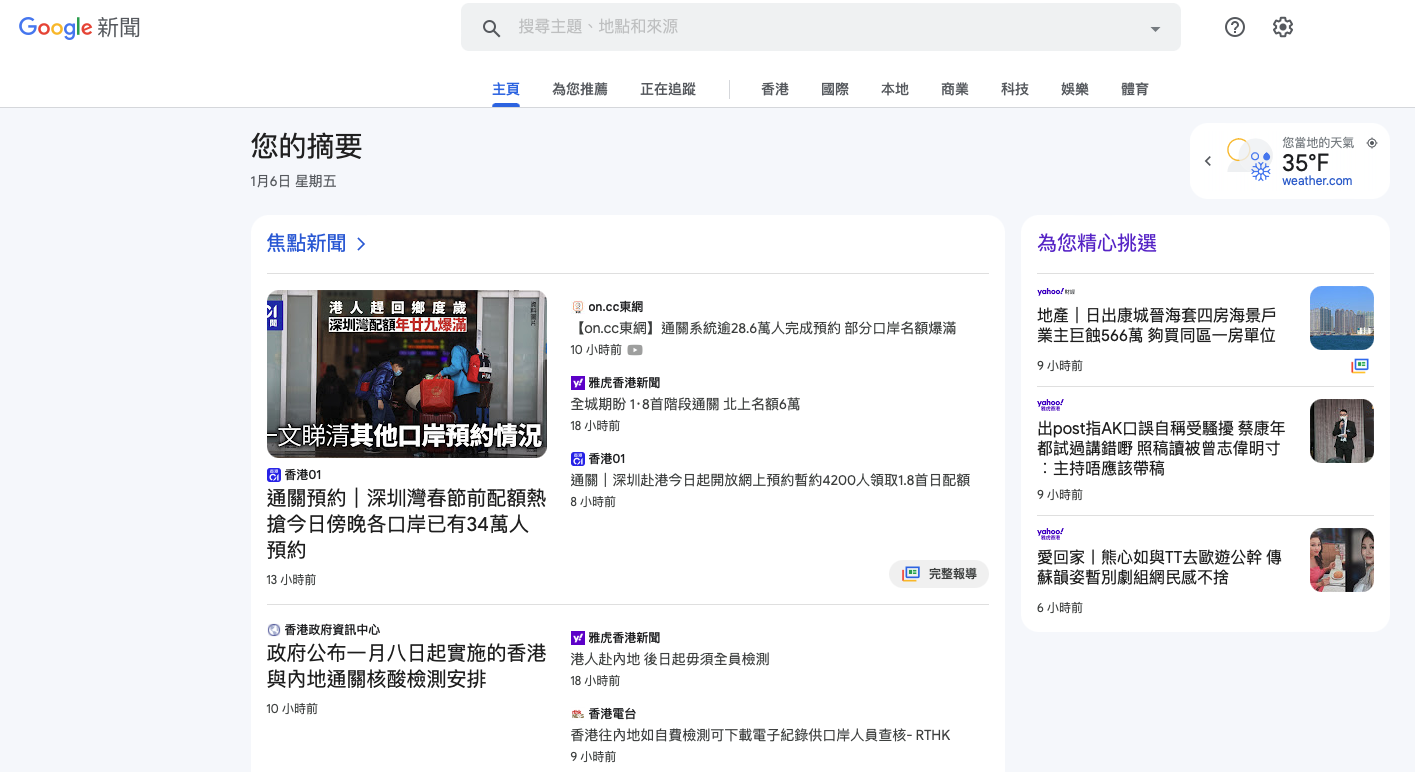
When you are viewing a webpage, the website is sending a sequence of integers to your web browser, with a recommendation about how they are supposed to be translated into characters. So, if your character encoding does not match the one intended by the web page, you will see garbled text. For example, let’s go to the news page of Google Hong Kong https://news.google.com/home?hl=zh-HK&gl=HK&ceid=HK:zh-Hant. On this page, you see some traditional Chinese characters and they are displayed correctly.
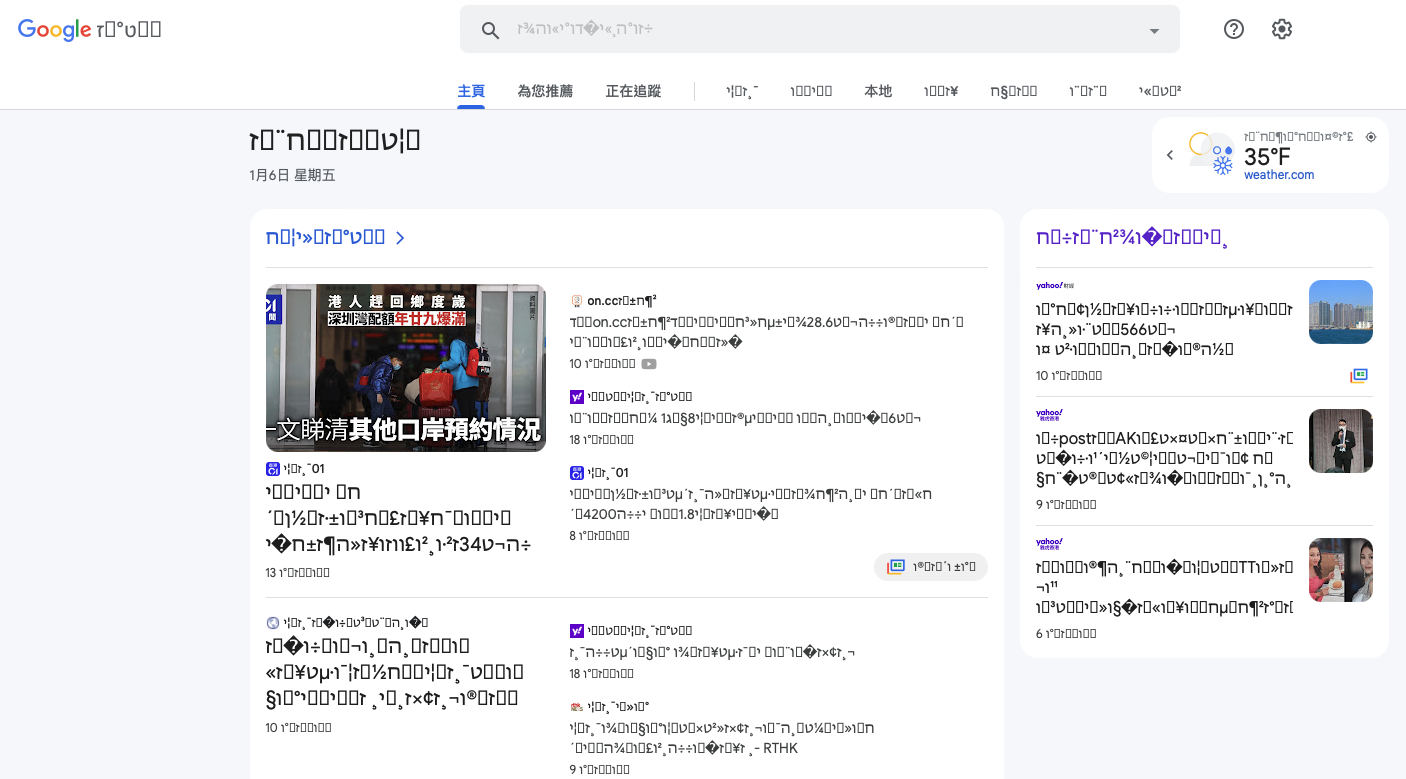
As soon as I change the text encoding to ISO 8859-8, which is used to encode Hebrew characters, you see that the text becomes garbage.
An example#
Let’s use the text file polish-lat2.txt in NLTK as an example. As the name suggests, this file is in Polish and is encoded as Latin2.
# Import nltk and download the sample files
import nltk
nltk.download('unicode_samples', download_dir='../data/nltk_data')
# Locate the file
path = nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
# Use Python3 to read the file
with open(path, 'r', encoding='latin2') as f:
pol_data=f.read()
print(pol_data)
Everything looks fine. This is because we have specified the encoding method of the original file correctly. What will happen if we read the file using the wrong encoding method? For example, if we open the file and specify the encoding as utf8 instead of latin2, what will happen?
# Use the wrong encoding utf8 to read the file
with open(path, 'r', encoding='utf8') as f:
pol_data=f.read()
print(pol_data)
We get an error! This is because in different encodings, the inventory of characters are different and the valid bytes the characters are encoded into are different as well. In our example, 0xf1 is a valid byte in latin2 but is not a valid byte in utf8.
In real life, instead of an error message, we often see a question mark � or a box in place of the character that cannot be correctly rendered.
# Specify that when error occurs, fill in replacement character
with open(path, 'r', encoding='utf8', errors='replace') as f:
pol_data_replace=f.read()
print(pol_data_replace)
Let’s encode the Polish data into bytes in latin2. The letter b prefixed to the string indicates that this is a byte string. You may wonder why some characters stay the same but others are turned into hex bytes. This is because only non-ASCII characters are converted to hex decimal representations.
# Encode the Polish data into latin2 bytes
pol_bytes = pol_data.encode(encoding='latin2')
pol_bytes
What does all this mean to Named Entity Recognition?#
Now, we understand why ‘plain text’ is just a mystery. Computers ultimately only get a sequence of numbers and what characters those numbers translate to depends on the encoding.
For those who work with multilingual corpora, especially those who work with texts that were created before the modern day, you will encounter at some point corpora that contain multiple encodings. We can use Python, however, to read a different encoding, standardize it into utf-8, and then continue to open that file as a utf-8 file consistently in the future.
# Use Python3 to read the file
with open(path, 'r', encoding='latin2') as f:
pol_data=f.read()
print(pol_data)
# Write the data with the encoding utf8 to another file
with open('../data/pol_lat2_to_utf8.txt', 'w', encoding='utf8') as f:
f.write(pol_data)
# Open the new file using utf8
with open('../data/pol_lat2_to_utf8.txt', 'r', encoding='utf8') as f:
pol_utf8=f.read()
print(pol_utf8)
Recall the non-ASCII character ń that gives us an issue? We can see how it looks like at the byte level in utf8.
# Encode the Polish data into utf8 bytes
pol_utf8_bytes = pol_utf8.encode('utf8')
pol_utf8_bytes
When we print out the Polish data from the file encoded in latin2 and from the one encoded in utf8, we get two strings on the screen that look exactly the same. However, when we get the byte strings from the two files, we see that even if two characters look the same to our naked eye, e.g. ń, they are different at the byte level. This means the computer will see them as two different characters.
Again, for those who work with multilingual corpora, you will encounter at some point corpora that contain multiple encodings. So, always convert your data to utf8 before proceeding to tokenization and NER.
Coding Challenge! < / >
Here is a txt file that is encoded in ISO-8859-15. Can you convert it to a utf-8 file?
import urllib.request
from pathlib import Path
# Check if a data folder exists. If not, create it.
data_folder = Path('../data/')
data_folder.mkdir(exist_ok=True)
# Download the file
url = 'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/iso_text.txt'
urllib.request.urlretrieve(url, '../data/' + url.rsplit('/', 1)[-1])
print('Sample file ready.')
Problems within UTF-8#
Our problems with encodings, unfortunately, do not end with UTF-8. Once we have encoded our texts into UTF-8, we can still have issues with characters that look the same but being encoded differently. This is particularly true with accented characters.
Here we have two characters that look exactly the same and are also deemed the same by the computer.
# Two characters that look exactly the same are deemed the same
"Ç" == "Ç"
Here, we also have two characters that look exactly the same but this time they are deemed as two different characters by the computer.
# Two characters that look exactly the same are not deemed the same
"Ç" == "Ç"
The two characters are regarded as different by the computer because at the byte level, they are different.
# Print out the unicode strings for the two characters
print("\u00C7", "\u0043\u0327")
One of them is seen as a single character, the accented C.
# Latin capital letter C with cedilla
accent_c = "\u00C7"
print(accent_c)
The other is seen as a compound character, consisting of two characters, one being the Latin letter C and the other being the ‘combining cedilla’ character.
# 'Latin capital letter C' and 'combining cedilla' characters together
compound_c = "\u0043\u0327"
print(compound_c)
The ‘combining cedilla’ character can be combined with other letters.
# Another example of compound character
"J\u0327"
# Take a look at the two parts of the compound C
"\u0043 \u0327"
Because the compound C and the accented C are different at the byte level, they are not considered the same by the computer.
# Two different byte strings for the two characters
"\u00C7" == "\u0043\u0327"
Unicode normalization#
In NER though, we will not want our NER model to interpret the two characters as two different characters. Therefore, we will need to first normalize them to make them the same at the byte level.
import unicodedata
Name |
Abbreviation |
Description |
Example |
|---|---|---|---|
Form D |
NFD |
Canonical decomposition |
|
Form C |
NFC |
Canoncial decomposition followed by canonical composition |
|
Source: James Briggs - https://towardsdatascience.com/what-on-earth-is-unicode-normalization-56c005c55ad0
# compound C and accented C
print(compound_c, accent_c)
print("\u00C7", "\u0043\u0327")
# Decompose the accented character using Normal Form D
nfd_accent = unicodedata.normalize('NFD', accent_c)
print(compound_c == nfd_accent)
# Decompose and then compose using Normal Form C
nfc_compound = unicodedata.normalize('NFC', compound_c)
print(accent_c == nfc_compound)
Resources#
Tim Scott from Computerphile explains UTF-8

James Briggs Explains Unicode Normalization

References#
Bird, S., Klein, E., & Loper, E. (2009). Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit. O’Reilly Media, Inc.
Spolsky, J. (2003, October 8). The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!). Joel on Software. https://www.joelonsoftware.com/2003/10/08/the-absolute-minimum-every-software-developer-absolutely-positively-must-know-about-unicode-and-character-sets-no-excuses/
Lesson Complete#
Congratulations! You have completed NER 1.
Start Next Lesson: NER 2#
Coding Challenge! Solutions#
There are often many ways to solve programming problems. Here are a few possible ways to solve the challenges, but there are certainly more!
# Convert an ISO-8859-15 file to utf-8
# Get the sample file
import urllib.request
url = 'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/iso_text.txt'
urllib.request.urlretrieve(url, '../data/' + url.rsplit('/', 1)[-1])
# Open the file in the correct encoding method and read in the data
with open('../data/iso_text.txt', encoding='iso-8859-15') as f:
text = f.read()
# create a new file in utf8 encoding and write in the data
with open('../data/iso_to_utf8.txt', 'w', encoding='utf8') as f:
f.write(text)
# Check the new file can be opened in utf8 encoding
with open('../data/iso_to_utf8.txt', 'r', encoding='utf8') as f:
data = f.read()
print(data)