This notebook was created by William Mattingly for the 2022 Text Analysis Pedagogy Institute, with support from the National Endowment for the Humanities, JSTOR Labs, and University of Arizona Libraries.
The exercises in this notebook are based on the notebooks created by Zoe LeBlanc for the 2021 Text Analysis Pedagogy Institute, with support from the National Endowment for the Humanities, JSTOR Labs, and University of Virginia Libraries.
This notebook is adapted by Zhuo Chen under Creative Commons CC BY License.
For questions/comments/improvements, email zhuo.chen@ithaka.org or nathan.kelber@ithaka.org
Multilingual NER 2#
This is lesson 2 of 3 in the educational series on multilingual NER. This notebook is focused on rules-based NER.
Description: This notebook describes how to:
Use spaCy to do rule-based NER
Create an EntityRuler
Identify Languages of a Corpus
Use case: For Learners (Detailed explanation, not ideal for researchers)
Difficulty: Intermediate
Completion time: 90 minutes
Knowledge Required:
Python Basics (start learning Python basics)
Knowledge Recommended: None
Data Format: .csv
Libraries Used: spaCy
Research Pipeline: None
Install required Python libraries#
%pip install spacy # for NLP and NER
%pip install pandas # for working with tabular data in the exercises of this notebook
!python -m spacy download en_core_web_sm # for English NER
!python -m spacy download es_core_news_sm # for Spanish NER
Introduction to spaCy#
The spaCy (spelled correctly) library is a robust library for Natural Language Processing. It supports a wide variety of languages with statistical models capable of parsing texts, identifying parts-of-speech, and extract entities.
Let’s see an example of NLP task that spaCy can do for us.
Tokenization#
Recall that last time we have seen a graph showing the NLP pipelines. A pipeline’s purpose is to take input data, perform some sort of operations on that input data, and then output some useful information from the data. On a pipeline, we find the pipes. A pipe is an individual component of a pipeline. Different pipes perform different tasks. After we read in the data from a text file, an essential task of NLP is tokenization.
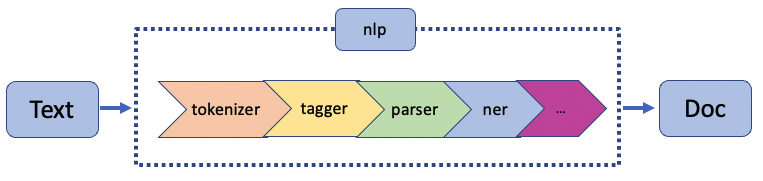
One form of tokenization is word tokenization. When we do word tokenization, we break a text up into individual words and punctuations. Another form of tokenization is sentence tokenization. Sentence tokenization is precisely the same as word tokenization, except instead of breaking a text up into individual words and punctuations, we break a text up into individual sentences.
If you are an English speaker, you may think you do not need spaCy for sentence tokenization, because in English, the end of a sentence is indicated by a period .. Why not just use the the built-in split() function which allows us to split a text string by the period .?
This is a ligit question, but simply splitting a text string by the period . will run into problems sometimes and spaCy is actually way more smarter.
# String to be split
text = "Martin J. Thompson is known for his writing skills. He is also good at programming."
# Split the string by period
sents = text.split(".")
print(sents)
['Martin J', ' Thompson is known for his writing skills', ' He is also good at programming', '']
We had the unfortunate result of splitting at Martin J. The reason for this is obvious. In English, it is common convention to indicate abbreviation with the same punctuation mark used to indicate the end of a sentence.
We can use SpaCy, however, to do sentence tokenization. SpaCy is smart enough to not break at Martin J.
First, let’s import the spaCy library. Then, we need to load an NLP model object. To do this, we use the spacy.load() function. Here, we load the small English NLP model trained on written web text that includes vocabulary, syntax and entities.
# Load the small English NLP model
import spacy
nlp = spacy.load("en_core_web_sm")
We can use this English NLP model to parse a text and create a Doc object. If you need a quick refresh about what classes and object are, you can refer to Python intermediate 4.
# Use the English model to parse the text we created
doc = nlp(text)
There is a lot of data stored in the Doc object. For example, we can iterate over the sentences in the Doc object and print them out.
# Get the sentence tokens in doc
for sent in doc.sents:
print(sent)
Martin J. Thompson is known for his writing skills.
He is also good at programming.
spaCy’s built-in NER#
We have seen one example NLP task that spaCy can do for us. Now let’s move on to named entity recognition, the NLP task we focus on in this series.
SpaCy already has a built-in NER off the shelf for us to use.
We will iterate over the doc object as we did above, but instead of iterating over doc.sents, we will iterate over doc.ents. For our purposes right now, we simply want to get each entity’s text (the string itself) and its corresponding label (note the underscore _ after label).
# Print out the entities in the doc object together with their labels
for ent in doc.ents: # iterate over the entities
print (ent.text, ent.label_)
Martin J. Thompson PERSON
As we can see the small English model has correctly identified that Martin J. Thompson is an entity and given it the correct label PERSON.
Of course we have many different kinds of entities. Here is a list of entity labels used by the small English NLP model we loaded.
# List of labels in the small English model for NER
nlp.get_pipe("ner").labels
('CARDINAL',
'DATE',
'EVENT',
'FAC',
'GPE',
'LANGUAGE',
'LAW',
'LOC',
'MONEY',
'NORP',
'ORDINAL',
'ORG',
'PERCENT',
'PERSON',
'PRODUCT',
'QUANTITY',
'TIME',
'WORK_OF_ART')
If you would like to know the meaning of a label, you can use the explain function.
# Get what a label means
spacy.explain('NORP')
'Nationalities or religious or political groups'
Coding Challenge! < / >
### Download the .csv file for this exercise
import urllib.request
from pathlib import Path
# Check if a data folder exists. If not, create it.
data_folder = Path('../data/')
data_folder.mkdir(exist_ok=True)
# Download the file
url = 'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/NER_Harry_Potter_1.csv'
urllib.request.urlretrieve(url, '../data/' + url.rsplit('/', 1)[-1])
print('Sample file ready.')
Sample file ready.
### Take a look at the first five rows of the table
import pandas as pd
df = pd.read_csv('../data/NER_Harry_Potter_1.csv', delimiter=';')
df.head()
| Character | Sentence | |
|---|---|---|
| 0 | Dumbledore | I should've known that you would be here, Prof... |
| 1 | McGonagall | Good evening, Professor Dumbledore. |
| 2 | McGonagall | Are the rumors true, Albus? |
| 3 | Dumbledore | I'm afraid so, professor. |
| 4 | Dumbledore | The good and the bad. |
In this table we find the name of the characters speaking and their speech.
Can you make two new columns, “Entities” and “Labels”, such that each row of the “Entities” column stores a list of entities found in the sentence in the same row and each row of the “Labels” column stores a list of labels for the entities?
spaCy’s EntityRuler#
Life would be so easy if we could just grab the ready-to-use built-in NER of spaCy and apply it to the large volume of data we have at hand. However, things are not that easy.
# Another sample text string
text = "Aars is a small town in Denmark. The town was founded in the 14th century."
#Create the Doc object
doc = nlp(text)
#extract entities
for ent in doc.ents:
print (ent.text, ent.label_)
Denmark GPE
the 14th century DATE
We see that the built-in NER failed to identify Aars as an entity of the GPE type. If we do want to extract ‘Aars’ from the text and give it a label of GPE, what can we do?
Add EntityRuler as a new pipe#
Recall that we have talked about the pipes in a pipeline at the beginning of this lesson. In the case of spaCy, there are a few different pipes that perform different tasks. The tokenizer tokenizes the text into individual tokens; the parser parses the text, and the NER identifies entities and labels them accordingly. When we create a Doc object, all of this data is stored in the Doc object.
# Take a look at the current pipes
nlp.pipe_names
['tok2vec', 'tagger', 'parser', 'attribute_ruler', 'lemmatizer', 'ner']
The EntityRuler is a spaCy factory that allows one to create a set of patterns with corresponding labels. In order to extract the target entities and label them successfully, we can create an EntityRuler, give it some instructions, and then add it to the spaCy pipeline as a new pipe.
# Create the EntityRuler
ruler = nlp.add_pipe("entity_ruler")
# List of Entities and Patterns
patterns = [
{"label": "GPE", "pattern": "Aars"}
]
ruler.add_patterns(patterns)
After we add the EntityRuler, we can use the new pipeline to do NER.
# Use the new model to parse the text and create a new Doc object
doc = nlp(text)
# Iterate over the entities and print them out
for ent in doc.ents:
print (ent.text, ent.label_)
Aars GPE
Denmark GPE
the 14th century DATE
# Take a look at the pipes in the new pipeline
nlp.pipe_names
['tok2vec',
'tagger',
'parser',
'attribute_ruler',
'lemmatizer',
'ner',
'entity_ruler']
The importance of order#
It is important to remember that pipelines are sequential. This means that components earlier in a pipeline affect what later components receive.
# Use the new model to parse a new text string
text = "Xiong'an is a satellite city of Beijing."
nlp1 = spacy.load("en_core_web_sm")
doc=nlp1(text)
for ent in doc.ents:
print(ent.text, ent.label_)
Xiong'an ORG
Beijing GPE
Xiong’an is a name of a city. We would want to label it as GPE, not ORG.
# Create the EntityRuler
ruler = nlp1.add_pipe("entity_ruler")
# List of Entities and Patterns
patterns = [
{"label": "GPE", "pattern": "Xiong'an"}
]
ruler.add_patterns(patterns)
# Get the entities
doc = nlp1(text)
for ent in doc.ents:
print(ent.text, ent.label_)
Xiong'an ORG
Beijing GPE
Why do we still mislabel Xiong’an? This is because when we add the EntityRuler as a new pipe, it gets added at the end of the pipeline automatically. That means the EntityRuler will come after the built-in NER in spaCy. Since NER is a hard classification task, an entity that gets labeled will not be relabeled. If Xiong’an is labeled already by the built-in NER as ORG, it will not be relabeled by the EntityRuler that comes after. In order to give the EntityRuler primacy, we will have to put it in a position before the built-in NER when we add it so that it takes primacy over the built-in NER.
# Load the model
nlp2 = spacy.load("en_core_web_sm")
# Create the EntityRuler and add it to the model
ruler = nlp2.add_pipe("entity_ruler", before='ner') # specify that the EntityRuler comes before built-in NER
# Add the new patterns to the ruler
patterns = [
{"label": "GPE", "pattern": "Xiong'an"}
]
ruler.add_patterns(patterns)
# Use the new model to parse the text
doc = nlp2(text)
# Get the entities
for ent in doc.ents:
print(ent.text, ent.label_)
Xiong'an GPE
Beijing GPE
# EntityRuler comes before the built in ner in nlp2
nlp2.pipe_names
['tok2vec',
'tagger',
'parser',
'attribute_ruler',
'lemmatizer',
'entity_ruler',
'ner']
So far, we only add exact strings to our EntityRuler. However, when we talk about patterns, we usually talk about more abstract patterns, not fixed strings. In the following, we will see an example where we write a regular expression pattern and add it to the EntityRuler.
Write a regex pattern#
Suppose we have a text written in English, except that the names are written in Latin.
# English text with Latin names
text = "Marius was a consul in Rome. Marie is the vocative form."
We could write a function that captures the different forms of the name Marius.
# Write a function that captures the pattern for the Latin name Marius
def pattern(root):
endings = ["us", "i", "o", "um", "e"] # the different endings of the name
patterns = [{"label": "PERSON", "pattern": root+ending} for ending in endings]
return patterns
marius = pattern("Mari")
marius
[{'label': 'PERSON', 'pattern': 'Marius'},
{'label': 'PERSON', 'pattern': 'Marii'},
{'label': 'PERSON', 'pattern': 'Mario'},
{'label': 'PERSON', 'pattern': 'Marium'},
{'label': 'PERSON', 'pattern': 'Marie'}]
# Create an empty English NLP model
nlp_latin = spacy.blank("en")
# Add an EntityRuler
nlp_latin_ruler = nlp_latin.add_pipe("entity_ruler")
# add the pattern for the Latin name Marius to the EntityRuler
nlp_latin_ruler.add_patterns(marius)
# Create a Doc object
doc_latin = nlp_latin(text)
# Iterate over the entities in Doc object and print them out
for ent in doc_latin.ents:
print (ent.text, ent.label_)
Marius PERSON
Marie PERSON
We could also use regex to help us write the pattern. If you would like to have a quick refresh of regular expressions, you can refer to the notebook Regular Expressions.
# Write a function which returns the pattern for Latin name Marius
def latin_roots(root):
return [{"label": "PERSON", "pattern": [{"TEXT": {"REGEX": "^" + root + r"(us|i|o|um|e)$"}}]}]
# Save the pattern to the variable marius2
marius2 = latin_roots("Mari")
# Create a blank English NLP model
nlp_latin2 = spacy.blank("en")
# Add an EntityRuler to the model
nlp_latin_ruler2 = nlp_latin2.add_pipe("entity_ruler")
# Add the pattern for Latin name Marius to the EntityRuler
nlp_latin_ruler2.add_patterns(marius2)
# Text to be parsed
text = "Marius was a consul in Rome. Marie is the vocative form. Caesar was a dictator."
# Create a Doc object using the new model with the regex pattern in EntityRuler
doc_latin2 = nlp_latin2(text)
# Iterate over the entities and print them out
for ent in doc_latin2.ents:
print(ent.text, ent.label_)
Marius PERSON
Marie PERSON
Coding Challenge! < / >
You have seen in coding challenge one that the off-the-shelf NER of Spacy mislabeled some entities. For example, “Hagrid”, a person’s name, is labeled as ORG. Suppose you have a file with all the characters’ names in it. Can you make an EntityRuler and add it to the SpaCy pipeline so that all the person names will be labeled ‘PERSON’.
### Download the .csv file for this exercise
import urllib.request
url = 'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/NER_HarryPotter_Characters.csv'
urllib.request.urlretrieve(url, '../data/' + url.rsplit('/', 1)[-1])
print('Sample file ready.')
Sample file ready.
# Read in the data from the character csv file
chars_df = pd.read_csv('../data/NER_HarryPotter_Characters.csv', delimiter=';')
# Take a look at the first five rows
chars_df.head()
| Id | Name | Gender | Job | House | Wand | Patronus | Species | Blood status | Hair colour | Eye colour | Loyalty | Skills | Birth | Death | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Harry James Potter | Male | Student | Gryffindor | 11" Holly phoenix feather | Stag | Human | Half-blood | Black | Bright green | Albus Dumbledore | Dumbledore's Army | Order o... | Parseltongue| Defence Against the Dark Arts | ... | 31 July 1980 | NaN |
| 1 | 2 | Ronald Bilius Weasley | Male | Student | Gryffindor | 12" Ash unicorn tail hair | Jack Russell terrier | Human | Pure-blood | Red | Blue | Dumbledore's Army | Order of the Phoenix | Hog... | Wizard chess | Quidditch goalkeeping | 1 March 1980 | NaN |
| 2 | 3 | Hermione Jean Granger | Female | Student | Gryffindor | 10¾" vine wood dragon heartstring | Otter | Human | Muggle-born | Brown | Brown | Dumbledore's Army | Order of the Phoenix | Hog... | Almost everything | 19 September, 1979 | NaN |
| 3 | 4 | Albus Percival Wulfric Brian Dumbledore | Male | Headmaster | Gryffindor | 15" Elder Thestral tail hair core | Phoenix | Human | Half-blood | Silver| formerly auburn | Blue | Dumbledore's Army | Order of the Phoenix | Hog... | Considered by many to be one of the most power... | Late August 1881 | 30 June, 1997 |
| 4 | 5 | Rubeus Hagrid | Male | Keeper of Keys and Grounds | Professor of Care... | Gryffindor | 16" Oak unknown core | NaN | Half-Human/Half-Giant | Part-Human (Half-giant) | Black | Black | Albus Dumbledore | Order of the Phoenix | Hogw... | Resistant to stunning spells| above average st... | 6 December 1928 | NaN |
# Get all parts from a character's name
chars_df = chars_df[['Name']]
chars_df['split_name'] = chars_df['Name'].str.split(' ')
chars_df
| Name | split_name | |
|---|---|---|
| 0 | Harry James Potter | [Harry, James, Potter] |
| 1 | Ronald Bilius Weasley | [Ronald, Bilius, Weasley] |
| 2 | Hermione Jean Granger | [Hermione, Jean, Granger] |
| 3 | Albus Percival Wulfric Brian Dumbledore | [Albus, Percival, Wulfric, Brian, Dumbledore] |
| 4 | Rubeus Hagrid | [Rubeus, Hagrid] |
| ... | ... | ... |
| 135 | Wilhelmina Grubbly-Plank | [Wilhelmina, Grubbly-Plank] |
| 136 | Fenrir Greyback | [Fenrir, Greyback] |
| 137 | Gellert Grindelwald | [Gellert, Grindelwald] |
| 138 | Dobby | [Dobby] |
| 139 | Kreacher | [Kreacher] |
140 rows × 2 columns
# Get the first names and last names of the characters
chars_df['first_name'] = chars_df['split_name'].str[0]
chars_df['last_name'] = chars_df['split_name'].str[-1]
first_names = chars_df['first_name'].unique().tolist() # Put all unique first names in a list
last_names = chars_df['last_name'].unique().tolist() # Put all unique last names in a list
names = list(set(first_names) | set(last_names)) # the vertical bar | gives us the union of the two sets
names
['Peter',
'Roger',
'Scrimgeour',
'Ravenclaw',
'Newton',
'James',
'Amos',
'Gideon',
'Abbott',
'Albus',
'Myrtle',
'Dolohov',
'Kingsley',
'Gabrielle',
'Snape',
'Severus',
'Blaise',
'Rodolphus',
'Rolanda',
'Salazar',
'Septima',
'Wilhelmina',
'Grindelwald',
'Theodore',
'Goyle',
'Sirius',
'Vance',
'Anthony',
'Bloody',
'Krum',
'Romilda',
'Shacklebolt',
'Antonin',
'Fabian',
'Rubeus',
'Diggle',
'Barty',
'Katie',
'Umbridge',
'Aberforth',
'Slytherin',
'Trelawney',
'Prewett',
'Montague',
'McGonagall',
'Sprout',
'Maxime',
'Horace',
'Fat',
'Granger',
'Tom',
'Goldstein',
'Davies',
'Filch',
'Fletcher',
'Granger-Weasley',
'Dudley',
'Edgecombe',
'Scorpius',
'Firenze',
'Petunia',
'Pomfrey',
'Potter',
'Hermione',
'Rookwood',
'Dolores',
'Moody',
'Vincent',
'Susan',
'Dumbledore',
'Nott',
'Clearwater',
'George',
'Viktor',
'Diggory',
'Ollivander',
'Lee',
'Weasley',
'Dorcas',
'Poppy',
'Rowena',
'Filius',
'Zabini',
'Patil',
'Macmillan',
'Millicent',
'Walden',
'Garrick',
'Mundungus',
'Cedric',
'Jordan\xa0',
'Cormac',
'Bellatrix',
'Vector',
'Malfoy',
'Marlene',
'Sinistra',
'Dean',
'Wood',
'Percy',
'Jr.',
'Lupin',
'Hestia',
'Edgar',
'Molly',
'Chang',
'Carrow',
'Finnigan',
'Gryffindor',
'Cuthbert',
'Longbottom',
'Remus',
'Alastor',
'Parkinson',
'Amycus',
'Ginevra',
'Godric',
'Riddle',
'Narcissa',
'Penelope',
'Pettigrew',
'Creevey',
'Fudge',
'Marietta',
'Neville',
'Dobby',
'Gregory',
'Kreacher',
'Flint',
'Yaxley',
'Grubbly-Plank',
'Bell',
'Arthur',
'Regulus',
'Burbage',
'Michael',
'Graham',
'Edward',
'Flitwick',
'Sr.',
'Smith',
'McLaggen',
'Charity',
'Irma',
'Minerva',
'Argus',
'Pomona',
'Rufus',
'Macnair',
'Gellert',
'Greyback',
'Helena',
'Belby',
'Gilderoy',
'Marcus',
'Fleur',
'Spinnet',
'Doge',
'Baron',
'Helga',
'Cornelius',
'Angelina',
'Ernest',
'Madame',
'Ronald',
'Podmore',
'Lockhart',
'Harry',
'Scamander',
'Jones',
'Dedalus',
'Lucius',
'Mimsy-Porpington',
'Slughorn',
'Sturgis',
'Pince',
'Finch-Fletchley',
'Fenrir',
'Justin',
'Hagrid',
'Igor',
'Karkaroff',
'Brown',
'Terry',
'Delacour',
'Lavender',
'Fred',
'Hannah',
'Binns',
'McKinnon',
'Charles',
'Draco',
'Corban',
'Bones',
'Rose',
'Hooch',
'Elphias',
'Bill',
'Quirinus',
'Vernon',
'Sybill',
'Augustus',
'Alice',
'Aurora',
'Dursley',
'Fenwick',
'Luna',
'Pansy',
'Lily',
'Frank',
'Marge',
'Padma',
'Dennis',
'Cho',
'Nymphadora',
'Tonks',
'Parvati',
'Meadowes',
'Thomas',
'Crabbe',
'Quirrell',
'Seamus',
'Corner',
'Oliver',
'Nicholas',
'Benjy',
'Johnson',
'Hufflepuff',
'Lestrange',
'Vane',
'Colin',
'Alicia',
'Boot',
'Friar',
'Lovegood',
'Bulstrode',
'Emmeline',
'Black',
'Zacharias',
'Alecto']
Create an EntityRuler. In the ruler, add all characters’ names as pattern and specify the label for them as “PERSON”. Add the ruler as a new pipe. Last, add two new columns to the dataframe you created from the original NER_Harry_Potter_1.csv file, one storing the entities found in each sentence and one storing the labels for the entities. This time, all characters’ names should be correctly labeled as “PERSON”.
Detecting languages in texts#
When we work with a multilingual corpus, we will first want to know the different languages used in the corpus. There are different approaches to do this. In this section, I will introduce a third-party library Lingua for language detection. Currently, 75 languages are supported by Lingua. Lingua is an open-source project and the github repository for Lingua is here pemistahl/lingua-py.
Language detection with Lingua#
# Install language detector
%pip install lingua-language-detector
# import the language detector builder
from lingua import LanguageDetectorBuilder
# build a language detector
detector = LanguageDetectorBuilder.from_all_languages().build()
# Use the detector to detect the language of a string
detector.detect_language_of("This is an English text")
Language.ENGLISH
# Use the detector to detect the language of a string
detector.detect_language_of("Este é um outro texto sem idioma especificado")
Language.PORTUGUESE
# Use the detector to detect the language of a string
detector.detect_language_of("这是一句中文")
Language.CHINESE
Sometimes you may already know the range of languages in your corpus. You just want to identify the language for each document. In this case, you could narrow down the language detector to only a few languages.
# build a language detector
from lingua import Language, LanguageDetectorBuilder
languages = [Language.ENGLISH, Language.FRENCH, Language.GERMAN, Language.SPANISH]
detector = LanguageDetectorBuilder.from_languages(*languages).build()
# Use the detector to decide between the given languages
detector.compute_language_confidence_values("This is an English text")
[ConfidenceValue(language=Language.ENGLISH, value=0.8163355284087402),
ConfidenceValue(language=Language.GERMAN, value=0.10768069612925102),
ConfidenceValue(language=Language.SPANISH, value=0.04162730578353555),
ConfidenceValue(language=Language.FRENCH, value=0.03435646967847322)]
Multiple languages in the same file#
The examples we go over just now assume that only one language is used in each document. However, the language detector we build cannot reliably detect multiple languages, because it will only output one language for a text by default. What if our text has multiple languages, such as the example below?
# a text string with multiple languages
large_text = '''This is a text where the first line is in English.
Maar de tweede regel is in het Nederlands.
Dies ist ein deutscher Text.'''
# build a language detector
languages = [Language.ENGLISH, Language.DUTCH, Language.GERMAN]
detector = LanguageDetectorBuilder.from_languages(*languages).build()
If we run the detector over this text, we get the following output.
# Use the detector to decide the language of the text
detector.detect_language_of(large_text)
Language.DUTCH
By default, Lingua returns the most likely language for a given input text.
confidence_values = detector.compute_language_confidence_values(large_text)
for confidence_value in confidence_values:
print(f"{confidence_value.language.name}: {confidence_value.value:.2f}")
DUTCH: 0.64
GERMAN: 0.26
ENGLISH: 0.11
But this text has multiple languages. In this example text, each sentence is written in a different language. Therefore, we need to get each sentence string and run the detector over it.
# Create a Doc object
doc = nlp(large_text)
# Iterate over each sentence and run the detector over it
for sent in doc.sents:
print(f"Sentence: {sent.text.strip()}")
print(detector.detect_language_of(sent.text))
Sentence: This is a text where the first line is in English.
Language.ENGLISH
Sentence: Maar de tweede regel is in het Nederlands.
Language.DUTCH
Sentence: Dies ist ein deutscher Text.
Language.GERMAN
Bring everything together#
# A document that has two languages, English and Spanish
multilingual_document = """This is a story about Margaret who speaks Spanish.
'Juan Miguel es mi amigo y tiene veinte años.' Margeret said to her friend Sarah.
"""
# build a language detector
from lingua import Language, LanguageDetectorBuilder
languages = [Language.ENGLISH, Language.FRENCH, Language.GERMAN, Language.SPANISH]
detector = LanguageDetectorBuilder.from_languages(*languages).build()
# Load the relevant models
english_nlp = spacy.load("en_core_web_sm") # for English
spanish_nlp = spacy.load("es_core_news_sm") # for Spanish
# Create an NLP model and create a Doc object
multi_nlp = spacy.blank('en')
# Add sentencizer
multi_nlp.add_pipe('sentencizer')
# Create a Doc object
multi_doc = multi_nlp(multilingual_document.strip())
# Switching between languages with conditionals
for sent in multi_doc.sents:
if detector.detect_language_of(sent.text).name == "ENGLISH":
nested_doc = english_nlp(sent.text.strip())
elif detector.detect_language_of(sent.text).name == "SPANISH":
nested_doc = spanish_nlp(sent.text.strip())
for ent in nested_doc.ents:
print(ent.text, ent.label_)
Margaret PERSON
Spanish LANGUAGE
Juan Miguel PER
Margeret PERSON
Sarah PERSON
Lesson Complete#
Congratulations! You have completed NER 2.
Start Next Lesson: NER 3#
Coding Challenge! Solutions#
There are often many ways to solve programming problems. Here are a few possible ways to solve the challenges, but there are certainly more!
Exercise 1 In the code cell below, we add two new columns to the dataframe created from NER_Harry_Potter_1.csv, one storing the entities found in each sentence using the off-the-shelf NER in spaCy, one storing the labels for the entities.
# Import libraries
import spacy
import pandas as pd
# Read in the data
df = pd.read_csv('../data/NER_Harry_Potter_1.csv', delimiter=';')
# Load the English model
nlp = spacy.load("en_core_web_sm")
# Make two new columns to store entities and labels
df['Entities'] = df['Sentence'].apply(lambda r: [ent.text for ent in nlp(r).ents])
df['Labels'] = df['Sentence'].apply(lambda r: [ent.label_ for ent in nlp(r).ents])
# Take a look at the updated df
df
Exercise 2 In the code cell below, we create an EntityRuler. We get all the character names and specify their label as “PERSON” in the ruler. We add this EntityRuler to the pipeline. Last, we add two new columns to the dataframe created from NER_Harry_Potter_1.csv, one storing the entities found in each sentence using the updated pipeline, one storing the labels for the entities. This time, all character names are correctly labeled as “PERSON”.
# Read in the data from the character csv file
chars_df = pd.read_csv('../data/NER_HarryPotter_Characters.csv', delimiter=';')
# Remove the irrelavant columns and only maintain the 'Name' column
chars_df = chars_df[['Name']]
# Create a new column storing the parts of each name
chars_df['split_name'] = chars_df['Name'].str.split(' ')
# Get the first names and last names of the characters
chars_df['first_name'] = chars_df['split_name'].str[0]
chars_df['last_name'] = chars_df['split_name'].str[-1]
first_names = chars_df['first_name'].unique().tolist() # Put all unique first names in a list
last_names = chars_df['last_name'].unique().tolist() # Put all unique last names in a list
# Get all unique names and put them in a list
names = list(set(first_names) | set(last_names)) # the vertical bar | gives us the union of the two sets
# Load the English model
nlp_ex = spacy.load("en_core_web_sm")
# Create a new EntityRuler and add it as a new pipe
ruler = nlp_ex.add_pipe("entity_ruler", before='ner')
patterns = [{"label": "PERSON", "pattern": name} for name in names]
ruler.add_patterns(patterns)
# Read in the data from the character and speech file
df = pd.read_csv('../data/NER_Harry_Potter_1.csv', delimiter=';')
# Make two new columns to store entities and labels
df['Entities'] = df['Sentence'].apply(lambda r: [ent.text for ent in nlp_ex(r).ents])
df['Labels'] = df['Sentence'].apply(lambda r: [ent.label_ for ent in nlp_ex(r).ents])
# Take a look at the updated df
df