This notebook was created by William Mattingly for the 2022 Text Analysis Pedagogy Institute, with support from the National Endowment for the Humanities, JSTOR Labs, and University of Arizona Libraries and Zoe LeBlanc for the 2021 Text Analysis Pedagogy Institute, with support from the National Endowment for the Humanities, JSTOR Labs, and University of Virginia Libraries.
This notebook is adapted by Zhuo Chen under Creative Commons CC BY License.
For questions/comments/improvements, email zhuo.chen@ithaka.org or nathan.kelber@ithaka.org.
Multilingual NER 3#
This is lesson 3 in the educational series on named entity recognition.
Description: This notebook describes:
how to understand word embeddings as a concept
how to understand Machine Learning as a concept
how to understand supervised learning
how to do NER ML in spaCy 3
Use case: Explanation
Difficulty: Intermediate
Completion time: 75 minutes
Knowledge Required:
Python basics (start learning Python basics)
Python intermediate 4 (OOP, classes, instances, inheritance)
Knowledge Recommended:
Basic file operations (start learning file operations)
Data cleaning with
Pandas(start learning Pandas)
Install libraries#
%pip install spacy # for NLP
%pip install pandas # for making tabular data
!python -m spacy download en_core_web_sm # for English NER
!python -m spacy download en_core_web_md # for showing the word vectors
Requirement already satisfied: spacy in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (3.8.7)
Requirement already satisfied: spacy-legacy<3.1.0,>=3.0.11 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (3.0.12)
Requirement already satisfied: spacy-loggers<2.0.0,>=1.0.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (1.0.5)
Requirement already satisfied: murmurhash<1.1.0,>=0.28.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (1.0.13)
Requirement already satisfied: cymem<2.1.0,>=2.0.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (2.0.11)
Requirement already satisfied: preshed<3.1.0,>=3.0.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (3.0.10)
Requirement already satisfied: thinc<8.4.0,>=8.3.4 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (8.3.6)
Requirement already satisfied: wasabi<1.2.0,>=0.9.1 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (1.1.3)
Requirement already satisfied: srsly<3.0.0,>=2.4.3 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (2.5.1)
Requirement already satisfied: catalogue<2.1.0,>=2.0.6 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (2.0.10)
Requirement already satisfied: weasel<0.5.0,>=0.1.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (0.4.1)
Requirement already satisfied: typer<1.0.0,>=0.3.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (0.16.0)
Requirement already satisfied: tqdm<5.0.0,>=4.38.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (4.67.1)
Requirement already satisfied: numpy>=1.19.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (2.3.1)
Requirement already satisfied: requests<3.0.0,>=2.13.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (2.32.4)
Requirement already satisfied: pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (2.11.7)
Requirement already satisfied: jinja2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (3.1.6)
Requirement already satisfied: setuptools in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (78.1.1)
Requirement already satisfied: packaging>=20.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (25.0)
Requirement already satisfied: langcodes<4.0.0,>=3.2.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from spacy) (3.5.0)
Requirement already satisfied: language-data>=1.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from langcodes<4.0.0,>=3.2.0->spacy) (1.3.0)
Requirement already satisfied: annotated-types>=0.6.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy) (0.7.0)
Requirement already satisfied: pydantic-core==2.33.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy) (2.33.2)
Requirement already satisfied: typing-extensions>=4.12.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy) (4.14.1)
Requirement already satisfied: typing-inspection>=0.4.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pydantic!=1.8,!=1.8.1,<3.0.0,>=1.7.4->spacy) (0.4.1)
Requirement already satisfied: charset_normalizer<4,>=2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from requests<3.0.0,>=2.13.0->spacy) (3.4.2)
Requirement already satisfied: idna<4,>=2.5 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from requests<3.0.0,>=2.13.0->spacy) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from requests<3.0.0,>=2.13.0->spacy) (2.5.0)
Requirement already satisfied: certifi>=2017.4.17 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from requests<3.0.0,>=2.13.0->spacy) (2025.7.14)
Requirement already satisfied: blis<1.4.0,>=1.3.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from thinc<8.4.0,>=8.3.4->spacy) (1.3.0)
Requirement already satisfied: confection<1.0.0,>=0.0.1 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from thinc<8.4.0,>=8.3.4->spacy) (0.1.5)
Requirement already satisfied: click>=8.0.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from typer<1.0.0,>=0.3.0->spacy) (8.2.1)
Requirement already satisfied: shellingham>=1.3.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from typer<1.0.0,>=0.3.0->spacy) (1.5.4)
Requirement already satisfied: rich>=10.11.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from typer<1.0.0,>=0.3.0->spacy) (14.0.0)
Requirement already satisfied: cloudpathlib<1.0.0,>=0.7.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from weasel<0.5.0,>=0.1.0->spacy) (0.21.1)
Requirement already satisfied: smart-open<8.0.0,>=5.2.1 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from weasel<0.5.0,>=0.1.0->spacy) (7.3.0.post1)
Requirement already satisfied: wrapt in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from smart-open<8.0.0,>=5.2.1->weasel<0.5.0,>=0.1.0->spacy) (1.17.2)
Requirement already satisfied: marisa-trie>=1.1.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from language-data>=1.2->langcodes<4.0.0,>=3.2.0->spacy) (1.2.1)
Requirement already satisfied: markdown-it-py>=2.2.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from rich>=10.11.0->typer<1.0.0,>=0.3.0->spacy) (3.0.0)
Requirement already satisfied: pygments<3.0.0,>=2.13.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from rich>=10.11.0->typer<1.0.0,>=0.3.0->spacy) (2.19.2)
Requirement already satisfied: mdurl~=0.1 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from markdown-it-py>=2.2.0->rich>=10.11.0->typer<1.0.0,>=0.3.0->spacy) (0.1.2)
Requirement already satisfied: MarkupSafe>=2.0 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from jinja2->spacy) (3.0.2)
Note: you may need to restart the kernel to use updated packages.
Requirement already satisfied: pandas in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (2.3.1)
Requirement already satisfied: numpy>=1.23.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pandas) (2.3.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pandas) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pandas) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from pandas) (2025.2)
Requirement already satisfied: six>=1.5 in /Users/mearacox/opt/anaconda3/envs/spacy-env/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas) (1.17.0)
Note: you may need to restart the kernel to use updated packages.
Collecting en-core-web-sm==3.8.0
Downloading https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.8.0/en_core_web_sm-3.8.0-py3-none-any.whl (12.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.8/12.8 MB 36.3 MB/s eta 0:00:00 0:00:01
?25h✔ Download and installation successful
You can now load the package via spacy.load('en_core_web_sm')
Collecting en-core-web-md==3.8.0
Downloading https://github.com/explosion/spacy-models/releases/download/en_core_web_md-3.8.0/en_core_web_md-3.8.0-py3-none-any.whl (33.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 33.5/33.5 MB 46.8 MB/s eta 0:00:00a 0:00:01
?25hInstalling collected packages: en-core-web-md
Successfully installed en-core-web-md-3.8.0
✔ Download and installation successful
You can now load the package via spacy.load('en_core_web_md')
Introduction to word embeddings#
How do we represent word meanings in NLP? One way we can represent word meanings is to use word vectors. Word embeddings are vector representations of words.
Distributional hypothesis#
Word embeddings is inspired by the distributional hypothesis proposed by Harris (1954). This theory could be summarized as: words that have similar context will have similar meanings.
What does “context” mean in word embeddings? Basically, “context” means the neighboring words of a target word.
Consider the following example. If we choose “village” as the target word and choose a fixed size context window of 2, the two words before “village” and the two words after “village” will constitute the context of the target word.
Treblinka is a small village in Poland.
Word2Vec#
Google’s pre-trained word2vec model includes word vectors for a vocabulary of 3 million words and phrases that they trained on roughly 100 billion words from a Google News dataset. The vector length is 300 features, which means each of the 3 million words in the vocabulary is represented by a vector with 300 floating numbers. Word2Vec is one of the most popular techniques to learn word embeddings.
The training samples are the (target, context) pairs from the text data. For example, suppose your source text is the sentence “The quick brown fox jumps over the lazy dog”. If you choose “quick” as your target word and have set a context window of size 2, you will get three training samples for it, i.e. (quick, the), (quick, brown) and (quick fox).
McCormick, C. (2016, April 19). Word2Vec Tutorial - The Skip-Gram Model. Retrieved from http://mccormickml.com/
The word2vec model is trained to accomplish the following task: given the input word \(w_{1}\), for each word \(w_{2}\) in our vocab, how likely \(w_{2}\) is a context word of \(w_{1}\).
The network is going to learn the statistics from the number of times each (target, context) shows up. So, for example, if you have a text about kings, queens and kingdoms, the network is probably going to get many more training samples of (“King”, “Queen”) than (“King”, “kangaroo”). Therefore, if you give your trained model the word “King” as input, then it will output a much higher probability for “Queen” than it will for “kangaroo”.
Word vectors in SpaCy#
We have used the small English model from spaCy in the previous two notebooks. Actually, there are medium size and large size English models from spaCy as well. Both are trained using the word2vec family of algorithms.
import spacy
# Load the medium size English model from spaCy
nlp = spacy.load('en_core_web_md')
# Get the word vector for the word "King"
nlp("King").vector
array([-6.0644e-01, -5.1205e-01, 6.4921e-03, -2.9194e-01, -5.6515e-01,
-1.1523e-01, 7.7274e-02, 3.3561e-01, 1.1593e-01, 2.3516e+00,
5.1773e-02, -5.4229e-01, -5.7972e-01, 1.3220e-01, 2.8430e-01,
-7.9592e-02, -2.6762e-01, 1.8301e-01, -4.1264e-01, 2.0459e-01,
1.4436e-01, -1.8714e-01, -3.1393e-01, 1.7821e-01, -1.0997e-01,
-2.5584e-01, -1.1149e-01, 9.6212e-02, -1.6168e-01, 4.0055e-01,
-2.6115e-01, 5.3777e-01, -5.2382e-01, 2.7637e-01, 7.2191e-01,
6.0405e-02, -1.7922e-01, 1.8020e-01, -1.4381e-01, -1.4795e-01,
-8.1394e-02, 5.8282e-02, 2.2964e-02, -2.6374e-01, 1.0704e-01,
-4.5425e-01, -1.9964e-01, 3.7720e-01, -9.7784e-02, -3.1999e-01,
-7.8509e-02, 6.1502e-01, 7.1643e-02, -3.0930e-02, 2.1508e-01,
2.5280e-01, -3.1643e-01, 6.6698e-01, 1.9813e-02, -3.2311e-01,
2.9266e-02, -4.1403e-02, 2.8346e-01, -7.9143e-01, 1.3327e-01,
7.7231e-02, -1.8724e-01, -3.3146e-01, -2.0797e-01, -6.9326e-01,
-2.3412e-01, -6.8752e-02, 3.8252e-02, -3.2459e-01, -8.3609e-03,
1.2945e-01, -2.8316e-01, -5.7546e-01, 2.4336e-01, 5.6433e-01,
-7.1285e-01, -5.4738e-03, -2.3305e-01, -7.1578e-02, 4.8301e-01,
-3.4312e-01, 2.7365e-01, -1.1771e+00, -6.5800e-01, -1.9009e-01,
7.4287e-03, 3.2977e-01, -1.6647e-01, 2.6851e-01, 1.1811e-01,
-6.2440e-02, -4.9987e-02, 7.1011e-04, -5.6201e-02, -2.6696e-01,
3.1351e-01, 4.3955e-01, -8.8727e-02, -1.2315e-01, 1.8855e-01,
-1.0834e+00, -3.3041e-01, 5.7325e-01, -3.9947e-01, 1.4852e-02,
-3.6787e-01, 3.7842e-01, -2.8962e-01, -7.0543e-02, -5.8699e-02,
5.3076e-01, -1.2736e-01, -3.5724e-01, -1.5007e-01, 1.3823e-02,
-1.9497e-01, -3.7189e-01, 2.6255e-01, -7.6826e-02, 8.4217e-02,
-5.3640e-01, 1.7393e-01, -1.4698e-01, -1.1068e-01, 1.7709e-01,
-3.9556e-01, 1.0433e-01, 9.2675e-03, -1.2282e-01, -3.9842e-01,
-2.7758e-01, -6.9369e-01, 7.0128e-02, 8.2794e-02, 4.8342e-02,
-2.7038e+00, -1.6812e-01, 3.1413e-01, 2.4313e-02, -3.6423e-02,
1.9292e-01, 4.4872e-01, -4.5427e-01, -3.7271e-01, -9.9532e-01,
-1.3411e-01, -6.0312e-01, 1.6642e-01, -2.4611e-02, 6.6891e-01,
6.3476e-02, -1.1327e+00, -3.3786e-01, -1.2576e-02, 3.5344e-01,
2.6643e-01, -1.9404e-01, -1.9516e-01, 6.3670e-01, 2.1373e-01,
-2.8936e-01, -6.8847e-02, -1.9738e-01, -3.5305e-01, 1.0219e-01,
1.1744e-01, 3.7159e-02, 4.1041e-01, -1.3766e-02, -1.0325e-02,
1.0461e-02, 3.0697e-02, -3.3016e-01, 2.4668e-01, -2.6058e-01,
2.8665e-01, -7.8507e-02, 6.8945e-03, 1.0980e-01, -6.4179e-01,
2.4617e-03, -2.4693e-01, -1.1188e-02, 3.0838e-01, 4.5557e-01,
-6.2189e-01, 1.4873e-01, 3.5440e-01, 2.8642e-01, -2.4211e-01,
-1.2404e-01, 2.3326e-01, 1.9555e-01, -1.2425e-02, 1.9920e-01,
-1.7935e-01, 5.2031e-01, -4.3666e-01, 8.6211e-02, 1.7282e-01,
6.5266e-02, 2.8701e-01, 6.0238e-01, 3.1843e-01, -4.7646e-01,
-2.1181e-02, -2.7726e-01, 4.0253e-01, 3.9968e-01, 1.8580e-02,
-6.2663e-01, 3.4149e-01, 4.4687e-01, -4.6135e-01, 4.4174e-01,
-5.7541e-02, -1.9038e-02, -2.2626e-01, 5.8452e-02, -4.6681e-02,
-5.3295e-03, -1.8257e-03, 4.8565e-01, -4.6144e-01, -4.5877e-01,
-1.5891e-01, 1.3037e-01, -2.9183e-01, 6.9206e-02, -4.9825e-02,
5.5077e-01, 1.4730e-01, -1.9255e-01, -2.3916e-01, -1.9319e-01,
1.5643e-01, 3.3491e-01, -3.1913e-01, 2.0674e-01, 6.4556e-02,
-2.3195e-01, 1.2657e-01, -2.5131e-03, 1.1079e-01, 3.0436e-01,
6.9529e-02, 1.1027e-01, 2.6285e-01, -2.3103e-01, -2.8933e-01,
-5.0675e-02, -8.9796e-02, 2.5816e-01, -8.0917e-02, 3.3160e-01,
-3.5930e-01, 2.8336e-01, 1.4145e-01, 2.9012e-01, 1.5677e-01,
1.3225e-01, -5.0090e-01, 2.2110e-01, 6.9609e-01, -9.6917e-02,
-2.4966e-02, -2.9391e-01, -3.1240e-01, -3.8031e-01, -2.0604e-01,
1.5959e-01, -5.6155e-01, 2.9170e-01, -5.0459e-01, 6.5684e-02,
5.8594e-01, 1.3003e-02, 6.5874e-01, -4.7811e-01, 2.8794e-01,
3.5918e-01, 4.3347e-01, -4.2480e-01, 3.5892e-01, -6.0925e-01,
-7.1236e-01, 2.9490e-01, -2.1479e-01, 2.5658e-01, -1.9358e-01,
1.1057e+00, 2.2862e-01, 2.1859e-01, -1.9044e-01, -1.0253e-01],
dtype=float32)
# Get the size of the vector
nlp("King").vector.size
300
# Get the similarity between the two words "King" and "Queen"
nlp("King").similarity(nlp("Queen"))
0.38253095746040344
# Get the similarity between the two words "King" and "kangaroo"
nlp("King").similarity(nlp("kangaroo"))
0.2849182188510895
Introduction to Machine Learning#
How is word2vector model trained? The model is trained using a machine learning technique.
Machine learning is a branch of artificial intelligence. Traditionally the human writes the rules in a computer system to perform a specific task. In machine learning, we use statistics to write the rules for us.
The machine learning pipeline#

Let’s use a simple example to understand the ML pipeline. Suppose you are interested in the relationship between the size and the price of a house in your neighborhood. Specifically, you would like to use the size of a house to predict its price. You go to Redfin/Zillow and find the information about the recently sold houses in your neighborhood. You note down their size and sale price. You draw a scatter plot like the following to examine the data.
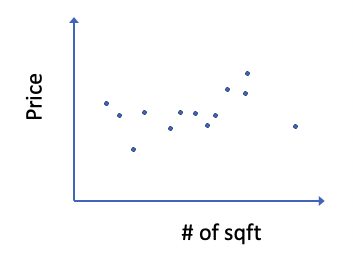
What you have in this scatter plot is your data. Now, you would like to derive a relationship between the house size and house price. Let’s use linear regression in this case. Essentially, you fit a line to the data points.
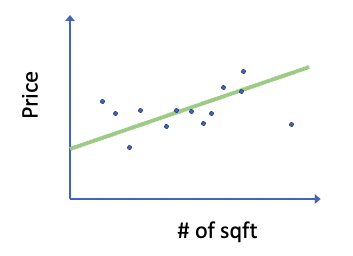
The function for this line is y = ax + b (where y is the price and x is the # of sqft). Of course, you would not just fit any line to your data points. You would want to fit a line so that the difference between the actual house prices and the predicted house prices is the smallest. Our task, then, reduces to the calculation of the value of a and b in the function y = ax + b so that the difference between the actual house prices and the predicted house prices is the smallest.
ML in Word2Vec#
The ML method used in word2vec is a shallow neural network with one hidden layer of neurons and one output layer of neurons. Chris McCormick has a very detailed explanation of this model in his blog post http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/. Let’s go take a look.
Supervised Learning#
Supervised learning is the process by which a system learns from a set of inputs that have known labels. To train a model, you first need training data – text examples, and the gold standard – labels you want the model to predict. This means that your training data need to be annotated.
Training and evaluation#
“When training a model, we don’t just want it to memorize our examples – we want it to come up with a theory that can be generalized across unseen data. After all, we don’t just want the model to learn that this one instance of “Amazon” right here is a company – we want it to learn that “Amazon”, in contexts like this, is most likely a company. That’s why the training data should always be representative of the data we want to process. A model trained on Wikipedia, where sentences in the first person are extremely rare, will likely perform badly on Twitter. Similarly, a model trained on romantic novels will likely perform badly on legal text.
This also means that in order to know how the model is performing, and whether it’s learning the right things, you don’t only need training data – you’ll also need evaluation data.”
https://spacy.io/usage/training
Honnibal, M., & Montani, I. (2017). spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing.
The training data is used to hone a statistical model via predetermined algorithms. It does this by making guesses about what the proper labels are. It then checks its accuracy against the correct labels, i.e., the annotated labels, and makes adjustments accordingly. Once it is finished viewing and guessing across all the training data, the first epoch, or iteration over the data, is finished. At this stage, the model then tests its accuracy against the evaluation data. The training data is then randomized and given back to the system for x number of epochs.
NER with EntityRuler vs. ML NER#
In this section, we are going to make two models to do the same NER task, one doing NER with an EntityRuler and the other doing NER using word vectors.
First, let’s download the two data files needed for this example.
import urllib.request
from pathlib import Path
# Check if a data folder exists. If not, create it.
data_folder = Path('../data/')
data_folder.mkdir(exist_ok=True)
# Download the files
urls = [
'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/NER_HarryPotter_FilmSpells.csv',
'https://ithaka-labs.s3.amazonaws.com/static-files/images/tdm/tdmdocs/NER_HarryPotter_Spells.csv',
]
for url in urls:
urllib.request.urlretrieve(url, '../data/' + url.rsplit('/', 1)[-1])
print('Sample files ready.')
Sample files ready.
The first file stores the information about the spells in Harry Potter.
import pandas as pd
spells_df = pd.read_csv('../data/NER_HarryPotter_Spells.csv', sep=";")
spells_df
| Name | Incantation | Type | Effect | Light | |
|---|---|---|---|---|---|
| 0 | Summoning Charm | Accio | Charm | Summons an object | NaN |
| 1 | Age Line | Unknown | Charm | Prevents people above or below a certain age f... | Blue |
| 2 | Water-Making Spell | Aguamenti | Charm, Conjuration | Conjures water | Icy blue |
| 3 | Launch an object up into the air | Alarte Ascendare | Charm | Rockets target upward | Red |
| 4 | Albus Dumbledore's Forceful Spell | Unknown | Spell | Great Force | NaN |
| ... | ... | ... | ... | ... | ... |
| 296 | Waddiwasi | Waddiwasi | Jinx | Propels wad at the target | NaN |
| 297 | Washing up spell | Unknown | Charm | Cleans dishes | NaN |
| 298 | Levitation Charm | Wingardium Leviosa | Charm | Makes objects fly | NaN |
| 299 | White sparks | Unknown | Charm | Jet of white sparks | White |
| 300 | Episkey | Episkey | Healing spell, Charm | Heals minor injuries | NaN |
301 rows × 5 columns
In the second file, we find the characters speaking and their speech. Notice that there is a column storing the spells found in the sentence if there is one.
film_spells = pd.read_csv('../data/NER_HarryPotter_FilmSpells.csv')
film_spells
| Character | Sentence | movie_number | identified_spells | |
|---|---|---|---|---|
| 0 | Dumbledore | I should've known that you would be here, Prof... | film 1 | NaN |
| 1 | McGonagall | Good evening, Professor Dumbledore. | film 1 | NaN |
| 2 | McGonagall | Are the rumors true, Albus? | film 1 | NaN |
| 3 | Dumbledore | I'm afraid so, professor. | film 1 | NaN |
| 4 | Dumbledore | The good and the bad. | film 1 | NaN |
| ... | ... | ... | ... | ... |
| 4923 | HERMIONE | How fast is it, Harry? | film 3 | NaN |
| 4924 | HARRY | Lumos. | film 3 | Lumos |
| 4925 | HARRY | I solemnly swear that I am up to no good. | film 3 | NaN |
| 4926 | HARRY | Mischief managed. | film 3 | NaN |
| 4927 | HARRY | Nox. | film 3 | Nox |
4928 rows × 4 columns
Suppose we would like to create a model that can identify spells in a sentence and give it the label ‘SPELL’.
Create an NLP model with an EntityRuler to identify the spells#
In the following, we will first create a NLP model with an entity ruler that identifies spells. This section can be seen as a review of what we have learned about EntityRuler in Wednesday’s lesson. Before we create a new EntityRuler, we will do some preprocessing of the data to get the patterns that we will add to the EntityRuler.
Preprocessing the data#
# Fill the NaN cells with an empty string
spells_df['Incantation'] = spells_df['Incantation'].fillna("")
# Get all spells
spells = spells_df['Incantation'].unique().tolist() # Put all strs in the 'Incantation' column in a list
spells = [spell for spell in spells if spell != ''] # Get all non-empty strs from the list, i.e. all the spells
# Take a look at the spells
spells
['Accio',
'Unknown',
'Aguamenti',
'Alarte Ascendare',
'Alohomora',
'Anapneo',
'Anteoculatia',
'Aparecium',
'Appare Vestigium',
'Aqua Eructo',
'Arania Exumai',
'Arresto Momentum',
'Ascendio',
'Avada Kedavra',
'Avifors\xa0',
'Avenseguim',
'Avis',
'Baubillious',
'Bombarda',
'Bombarda Maxima',
'Brackium Emendo',
'Calvorio',
'Cantis',
'Capacious extremis',
'Carpe Retractum',
'Cave inimicum',
'Circumrota',
'Cistem Aperio',
'Colloportus',
'Colloshoo',
'Colovaria',
'Confringo',
'Confundo',
'Crinus Muto',
'Crucio',
'Defodio',
'Deletrius',
'Densaugeo',
'Deprimo',
'Depulso',
'Descendo',
'Diffindo',
'Diminuendo',
'Dissendium',
'Draconifors',
'Ducklifors',
'Duro',
'Ebublio',
'Engorgio',
'Engorgio Skullus',
'Entomorphis',
'Epoximise',
'Erecto',
'Evanesce',
'Evanesco',
'Everte Statum',
'Expecto Patronum',
'Expelliarmus',
'Expulso',
'Ferula',
'Fianto Duri',
'Finestra',
'Finite',
'Flagrante',
'Flagrate',
'Flintifors',
'Flipendo',
'Flipendo Tria',
'Fumos',
'Fumos Duo',
'Furnunculus',
'Geminio',
'Glacius',
'Glacius Duo',
'Glacius Tria',
'Glisseo',
'Harmonia Nectere Passus',
'Herbifors',
'Herbivicus',
'Homenum Revelio',
'Illegibilus',
'Immobulus',
'Impedimenta',
'Imperio',
'Impervius ',
'Incarcerous',
'Incendio',
'Incendio Tria',
'Inflatus',
'Informous',
'Locomotor Wibbly',
'Lacarnum Inflamari',
'Langlock',
'Lapifors',
'Legilimens',
'Levicorpus',
'Liberacorpus',
'Locomotor',
'Locomotor Mortis',
'Lumos',
'Lumos Duo',
'Lumos Maxima',
'Lumos Solem',
'Magicus Extremos',
'Melofors',
'Meteolojinx Recanto',
'Mimblewimble',
'Mobiliarbus',
'Mobilicorpus',
'Molliare',
'Morsmordre',
'Mucus ad Nauseam',
'Muffliato ',
'Multicorfors ',
'Mutatio Skullus',
'Nox',
'Nebulus',
'Oculus Reparo',
'Obliviate\xa0',
'Obscuro',
'Oppugno ',
'Orbis',
'Orchideous',
'Oscausi',
'Pack',
'Papyrus Reparo',
'Partis Temporus',
'Periculum',
'Peskipiksi Pesternomi',
'Petrificus Totalus',
'Piertotum Locomotor',
'Piscifors',
'Point Me',
'Portus',
'Prior Incantato',
'Protego',
'Protego Diabolica',
'Protego horribilis',
'Protego Maxima',
'Protego totalum',
'Quietus',
'Redactum Skullus',
'Reducio',
'Reducto',
'Reparifors',
'Reverte',
'Relashio',
'Rennervate',
'Reparifarge',
'Reparo',
'Repello Muggletum',
'Repello Inimicum',
'Revelio',
'Rictusempra',
'Riddikulus',
'Salvio hexia',
'Scourgify',
'Sectumsempra',
'Serpensortia',
'Silencio',
'Skurge',
'Slugulus Eructo',
'Sonorus',
'Specialis Revelio',
'Spongify',
'Steleus',
'Stupefy',
'Surgito',
'Tarantallegra\xa0',
'Tentaclifors',
'Tergeo',
'Titillando',
'Ventus',
'Ventus Duo',
'Vera Verto',
'Verdillious',
'Verdimillious',
'Vermiculus',
'Vermillious',
'Vipera Evanesca',
'Vulnera Sanentur',
'Waddiwasi',
'Wingardium Leviosa',
'Episkey']
Creating the patterns to be added to the EntityRuler#
Recall from Wednesday’s lesson that the patterns we add to an EntityRuler look like the following.
patterns = [{"label": "GPE", "pattern": "Aars"}]
# Write the pattern to be added to the ruler
patterns = [{"label":"SPELL", "pattern":spell} for spell in spells]
Now that we have the patterns ready, we can add them to an EntityRuler and add the ruler as a new pipe.
# Create an EntityRuler and add the patterns to the ruler
entruler_nlp = spacy.blank('en') # Create a blank English model
ruler = entruler_nlp.add_pipe("entity_ruler")
ruler.add_patterns(patterns)
test_text = """Ron Weasley: Wingardium Leviosa! Hermione Granger: You're saying it wrong.
It's Wing-gar-dium Levi-o-sa, make the 'gar' nice and long.
Ron Weasley: You do it, then, if you're so clever"""
doc = entruler_nlp(test_text)
for ent in doc.ents:
print('EntRulerModel', ent.text, ent.label_)
EntRulerModel Wingardium Leviosa SPELL
In this model, we have basically hard written all spell strings in the EntityRuler.
Train a NLP model using ML to identify the spells#
The format of the training data will look like the following. It is a list of tuples. In each tuple, the first element is the text string containing spells and the second element is a dictionary. The key of the dictionary is ‘entities’. The value is a list of lists. In each list, we find the starting index, ending index and the label of the spell(s) found in the text string.
[ ('Oculus Reparo', {'entities': [[0, 13, 'SPELL']]}), ('Alohomora', {'entities': [[0, 9, 'SPELL']]}) ]
The text strings we use for the training are from the ‘Sentence’ column of the film_spells dataframe.
# Take a look at the film_spells df
film_spells
| Character | Sentence | movie_number | identified_spells | |
|---|---|---|---|---|
| 0 | Dumbledore | I should've known that you would be here, Prof... | film 1 | NaN |
| 1 | McGonagall | Good evening, Professor Dumbledore. | film 1 | NaN |
| 2 | McGonagall | Are the rumors true, Albus? | film 1 | NaN |
| 3 | Dumbledore | I'm afraid so, professor. | film 1 | NaN |
| 4 | Dumbledore | The good and the bad. | film 1 | NaN |
| ... | ... | ... | ... | ... |
| 4923 | HERMIONE | How fast is it, Harry? | film 3 | NaN |
| 4924 | HARRY | Lumos. | film 3 | Lumos |
| 4925 | HARRY | I solemnly swear that I am up to no good. | film 3 | NaN |
| 4926 | HARRY | Mischief managed. | film 3 | NaN |
| 4927 | HARRY | Nox. | film 3 | Nox |
4928 rows × 4 columns
Since we have hard written all spell strings in the EntityRuler and give them the label ‘SPELL’, we could just use this model to generate labeled data as our training data and evaluation data.
import nltk # for sentence tokenization
nltk.download('punkt')
def generate_labeled_data(ls_sents): # the input will be a list of strings
text = ' '.join(ls_sents)
sents = nltk.sent_tokenize(text)
labeled_data = []
for sent in sents:
doc = entruler_nlp(sent) # create a doc object
if doc.ents != (): # if there is at least one entity identified
labeled_data.append((sent, {"entities":[[ent.start_char, ent.end_char, ent.label_] for ent in doc.ents]}))
return labeled_data
# Assign the result from the function to a new variable
training_validation_data = generate_labeled_data(film_spells['Sentence'].tolist())
# Take a look at the labeled data
training_validation_data
[nltk_data] Downloading package punkt to /Users/mearacox/nltk_data...
[nltk_data] Package punkt is already up-to-date!
[('For example: Oculus Reparo.', {'entities': [[13, 26, 'SPELL']]}),
('Alohomora Get in Alohomora?',
{'entities': [[0, 9, 'SPELL'], [17, 26, 'SPELL']]}),
('Wingardium Leviosa.', {'entities': [[0, 18, 'SPELL']]}),
('Wingardium Leviosa.', {'entities': [[0, 18, 'SPELL']]}),
('Wingardium Leviosa!', {'entities': [[0, 18, 'SPELL']]}),
("Neville, I'm really, really sorry about this Petrificus Totalus.",
{'entities': [[46, 64, 'SPELL']]}),
('Alohomora.', {'entities': [[0, 9, 'SPELL']]}),
('Alohomora!', {'entities': [[0, 9, 'SPELL']]}),
('Oculus Reparo.', {'entities': [[0, 13, 'SPELL']]}),
('Peskipiksi Pesternomi!', {'entities': [[0, 21, 'SPELL']]}),
('Immobulus!', {'entities': [[0, 9, 'SPELL']]}),
('Vera Verto.', {'entities': [[0, 10, 'SPELL']]}),
('Vera Verto.', {'entities': [[0, 10, 'SPELL']]}),
('Vera Verto!', {'entities': [[0, 10, 'SPELL']]}),
('Finite Incantatem!', {'entities': [[0, 6, 'SPELL']]}),
('Brackium Emendo!', {'entities': [[0, 15, 'SPELL']]}),
('Expelliarmus!', {'entities': [[0, 12, 'SPELL']]}),
('Two... Everte Statum!', {'entities': [[7, 20, 'SPELL']]}),
('Rictusempra!', {'entities': [[0, 11, 'SPELL']]}),
('Serpensortia!', {'entities': [[0, 12, 'SPELL']]}),
('Alarte Ascendare!', {'entities': [[0, 16, 'SPELL']]}),
('Vipera Evanesca.', {'entities': [[0, 15, 'SPELL']]}),
('Wingardium Leviosa.', {'entities': [[0, 18, 'SPELL']]}),
('Cistem Aperio!', {'entities': [[0, 13, 'SPELL']]}),
('Arania Exumai!', {'entities': [[0, 13, 'SPELL']]}),
('Arania Exumai!', {'entities': [[0, 13, 'SPELL']]}),
('Arania Exumai!', {'entities': [[0, 13, 'SPELL']]}),
('Lumos Maxima... Lumos Maxima... Lumos Maxima... Lumos... MAXIMA!',
{'entities': [[0, 12, 'SPELL'],
[16, 28, 'SPELL'],
[32, 44, 'SPELL'],
[48, 53, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Listen: Riddikulus!', {'entities': [[8, 18, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Riddikulus!', {'entities': [[0, 10, 'SPELL']]}),
('Then speak the incantation, Expecto Patronum.',
{'entities': [[28, 44, 'SPELL']]}),
('Expecto Patronum.', {'entities': [[0, 16, 'SPELL']]}),
('Expecto Patronum!', {'entities': [[0, 16, 'SPELL']]}),
('Expecto Patronum!', {'entities': [[0, 16, 'SPELL']]}),
('Expecto Patronum!', {'entities': [[0, 16, 'SPELL']]}),
('Nox.', {'entities': [[0, 3, 'SPELL']]}),
('Expelliarmus!', {'entities': [[0, 12, 'SPELL']]}),
('Expelliarmus!', {'entities': [[0, 12, 'SPELL']]}),
('Expelliarmus!', {'entities': [[0, 12, 'SPELL']]}),
('Expelliarmus!', {'entities': [[0, 12, 'SPELL']]}),
('Expecto Patronum!', {'entities': [[0, 16, 'SPELL']]}),
('Immobulus!', {'entities': [[0, 9, 'SPELL']]}),
('Expecto Patronum!', {'entities': [[0, 16, 'SPELL']]}),
('Bombarda!', {'entities': [[0, 8, 'SPELL']]}),
('Lumos.', {'entities': [[0, 5, 'SPELL']]}),
('Nox.', {'entities': [[0, 3, 'SPELL']]})]
spaCy 3 requires that our data be stored in the proprietary .spacy format. To do that we need to use the DocBin class.
from spacy.tokens import DocBin
db = DocBin()
for text, annot in training_validation_data[:19*2]: # Get the first 38 tuples as the training data
doc = entruler_nlp(text) # create a doc object
doc.ents = [doc.char_span(ent[0], ent[1], label=ent[2]) for ent in annot['entities']]
db.add(doc)
db.to_disk(f"./train_spells.spacy")
for text, annot in training_validation_data[19*2:]: # Get the rest tuples as the validation data
doc = entruler_nlp(text)
doc.ents = [doc.char_span(ent[0], ent[1], label=ent[2]) for ent in annot['entities']]
db.add(doc)
db.to_disk(f"./valid_spells.spacy")
Now we can finally start training our model!
!python -m spacy init config --lang en --pipeline ner config.cfg --force
⚠ To generate a more effective transformer-based config (GPU-only),
install the spacy-transformers package and re-run this command. The config
generated now does not use transformers.
ℹ Generated config template specific for your use case
- Language: en
- Pipeline: ner
- Optimize for: efficiency
- Hardware: CPU
- Transformer: None
✔ Auto-filled config with all values
✔ Saved config
config.cfg
You can now add your data and train your pipeline:
python -m spacy train config.cfg --paths.train ./train.spacy --paths.dev ./dev.spacy
!python -m spacy train config.cfg --output ./output/spells-model/ --paths.train ./train_spells.spacy --paths.dev ./valid_spells.spacy
✔ Created output directory: output/spells-model
ℹ Saving to output directory: output/spells-model
ℹ Using CPU
=========================== Initializing pipeline ===========================
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'ner']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS NER ENTS_F ENTS_P ENTS_R SCORE
--- ------ ------------ -------- ------ ------ ------ ------
0 0 0.00 70.00 33.99 26.80 46.43 0.34
141 200 1.46 584.26 98.18 100.00 96.43 0.98
341 400 0.00 0.00 98.18 100.00 96.43 0.98
541 600 0.00 0.00 98.18 100.00 96.43 0.98
741 800 0.00 0.00 98.18 100.00 96.43 0.98
941 1000 0.00 0.00 98.18 100.00 96.43 0.98
1141 1200 0.00 0.00 98.18 100.00 96.43 0.98
1341 1400 0.00 0.00 98.18 100.00 96.43 0.98
1541 1600 0.00 0.00 98.18 100.00 96.43 0.98
1741 1800 0.00 0.00 98.18 100.00 96.43 0.98
✔ Saved pipeline to output directory
output/spells-model/model-last
Now let’s finally run our model!
# Load the best model
model_best = spacy.load('./output/spells-model/model-best')
# Let's try our model on this long text string
test_text = """53. Imperio - Makes target obey every command But only for really, really funny pranks. 52. Piertotum Locomotor - Animates statues On one hand, this is awesome. On the other, someone would use this to scare me.
51. Aparecium - Make invisible ink appear
Your notes will be so much cooler.
50. Defodio - Carves through stone and steel
Sometimes you need to get the eff out of there.
49. Descendo - Moves objects downward
You'll never have to get a chair to reach for stuff again.
48. Specialis Revelio - Reveals hidden magical properties in an object
I want to know what I'm eating and if it's magical.
47. Meteolojinx Recanto - Ends effects of weather spells
Otherwise, someone could make it sleet in your bedroom forever.
46. Cave Inimicum/Protego Totalum - Strengthens an area's defenses
Helpful, but why are people trying to break into your campsite?
45. Impedimenta - Freezes someone advancing toward you
"Stop running at me! But also, why are you running at me?"
44. Obscuro - Blindfolds target
Finally, we don't have to rely on "No peeking."
43. Reducto - Explodes object
The "raddest" of all spells.
42. Anapneo - Clears someone's airway
This could save a life, but hopefully you won't need it.
41. Locomotor Mortis - Leg-lock curse
Good for footraces and Southwest Airlines flights.
40. Geminio - Creates temporary, worthless duplicate of any object
You could finally live your dream of lying on a bed of marshmallows, and you'd only need one to start.
39. Aguamenti - Shoot water from wand
No need to replace that fire extinguisher you never bought.
38. Avada Kedavra - The Killing Curse
One word: bugs.
37. Repelo Muggletum - Repels Muggles
Sounds elitist, but seriously, Muggles ruin everything. Take it from me, a Muggle.
36. Stupefy - Stuns target
Since this is every other word of the "Deathly Hallows" script, I think it's pretty useful."""
# Create a doc object out of the text string using the trained model
doc = model_best(test_text)
# Find out the entities
for ent in doc.ents:
print(ent.text, ent.label_)
Animates SPELL
Aparecium - SPELL
Your SPELL
Defodio - SPELL
Sometimes you SPELL
of SPELL
Descendo SPELL
Specialis Revelio SPELL
Reveals SPELL
Meteolojinx Recanto SPELL
46 SPELL
Protego Totalum SPELL
Strengthens SPELL
Freezes SPELL
Stop SPELL
Obscuro - SPELL
Blindfolds SPELL
Reducto SPELL
Explodes SPELL
Anapneo - SPELL
Clears SPELL
41 SPELL
Locomotor Mortis SPELL
Southwest Airlines SPELL
40 SPELL
Aguamenti - SPELL
Shoot SPELL
Avada Kedavra SPELL
Killing Curse SPELL
Repelo Muggletum SPELL
Repels SPELL
Sounds SPELL
Muggle SPELL
Stupefy SPELL
Since SPELL
Deathly Hallows SPELL
Let’s also try the model we created with an EntityRuler with all spell names hard written in it.
# Create a doc object out of the text string using the EntityRuler model
doc = entruler_nlp(test_text)
# Find out the entities
for ent in doc.ents:
print(ent.text, ent.label_)
Imperio SPELL
Piertotum Locomotor SPELL
Aparecium SPELL
Defodio SPELL
Descendo SPELL
Specialis Revelio SPELL
Meteolojinx Recanto SPELL
Protego SPELL
Impedimenta SPELL
Obscuro SPELL
Reducto SPELL
Anapneo SPELL
Locomotor Mortis SPELL
Geminio SPELL
Aguamenti SPELL
Avada Kedavra SPELL
Stupefy SPELL
It seems in this example our EntityRuler model performs better than our trained model. Why do we think that is?
Part of the reason we aren’t getting better results is something that Ines Montani describes in this Stack Overflow answer https://stackoverflow.com/questions/50580262/how-to-use-spacy-to-create-a-new-entity-and-learn-only-from-keyword-list/50603247#50603247
“The advantage of training the named entity recognizer to detect SPECIES in your text is that the model won’t only be able to recognise your examples, but also generalise and recognise other species in context. If you only want to find a fixed set of terms and not more, a simpler, rule-based approach might work better for you.”
References#
McCormick, C. (2016, April 19). Word2Vec Tutorial - The Skip-Gram Model. Retrieved from http://www.mccormickml.com